Chaos-Tests: Schlüsselprinzipien, Vorteile und Implementierung
Im Jahr 2008 erlebte Netflix eine schwerwiegende Datenbankbeschädigung, die den DVD-Versand für drei Tage lahmlegte. Statt sich nur zu erholen und weiterzumachen, entschieden sie sich für einen proaktiven Ansatz. Sie überlegten: Wenn Ausfälle unvermeidlich sind, warum sie nicht absichtlich unter kontrollierten Bedingungen auslösen? Dieser Ansatz entwickelte sich schließlich zu dem, was wir heute als Chaos Testing oder Chaos Engineering kennen. Aber wie funktioniert es, und ist es immer noch relevant? Tauchen wir ein in die Frage, wie dieser Ansatz Ihre Teststrategie verändern und Ihnen helfen kann, widerstandsfähigere Anwendungen zu entwickeln.
Chaos Testing (oft auch Chaos Engineering genannt) ist ein disziplinierter Ansatz, um absichtlich Fehler in Ihr System einzuführen, um dessen Widerstandsfähigkeit zu testen. Aber lassen Sie sich vom Namen nicht täuschen – es gibt nichts Zufälliges oder wirklich Chaotisches daran.
Im Wesentlichen ist es eine Methodik, die Ihnen hilft, Schwachstellen in Ihren Systemen zu identifizieren, indem Sie reale Ausfallszenarien in einer kontrollierten Umgebung simulieren. Die Bedeutung des Chaos Testing geht über das bloße Zerstören von Dingen hinaus; es geht darum zu verstehen, wie Systeme auf Stress reagieren und ihre Fähigkeit zu verbessern, Störungen standzuhalten.
Chaos Testing umfasst:
Kontrollierte Experimente, die reale Ausfälle wie Serverabstürze, Netzwerkausfälle oder Latenzspitzen simulieren
Hypothesengesteuerte Methodik, bei der Sie vorhersagen, wie Ihr System auf Ausfälle reagieren sollte
Proaktive Entdeckung von Schwachstellen, bevor sie Benutzer in Produktionsumgebungen beeinträchtigen
Aufbau von Vertrauen in die Fähigkeit Ihres Systems, turbulenten Bedingungen standzuhalten
Im Gegensatz zu herkömmlichen Tests, die korrektes Verhalten unter idealen Bedingungen überprüfen, stellt Chaos Testing die unbequeme Frage: „Was passiert, wenn etwas schief geht?“ Es geht darum, die Grenzen Ihres Systems zu verstehen und sie zu beheben, bevor sie in Wirklichkeit brechen.
Geschichte des Chaos Testing
Die Entwicklung des Chaos Testing ist eine faszinierende Reise, die mit der schmerzhaften Erfahrung eines Unternehmens begann und sich zu einer populären Ingenieursdisziplin entwickelte:
2008: Netflix erleidet einen schwerwiegenden Datenbankbeschädigungsvorfall, der den DVD-Versand für drei Tage verhindert. Diese schmerzhafte Erfahrung wird zum Katalysator für die Entwicklung widerstandsfähigerer Systeme.
2010: Netflix beginnt mit der Migration von Rechenzentren zur AWS-Cloud-Infrastruktur, was die Systemkomplexität dramatisch erhöht.
2011: Netflix erstellt und implementiert Chaos Monkey, ein Tool, das zufällig Instanzen in der Produktion beendet, um zu überprüfen, ob Dienste unerwartete Ausfälle überleben können. Es ist nach der Idee benannt, einen wilden Affen mit einer Waffe in Ihrem Rechenzentrum freizusetzen, der zufällig Server zerstört.
2012: Netflix erweitert mit der „Simian Army“ – einer Suite von Tools, darunter Latency Monkey (Hinzufügen von Verzögerungen), Doctor Monkey (Erkennung ungesunder Instanzen) und Chaos Gorilla (Abschaltung ganzer Amazon-Verfügbarkeitszonen).
2014: Der Begriff „Chaos Engineering“ wurde offiziell von Netflix-Ingenieuren geprägt und etablierte ihn als Disziplin statt nur als Sammlung von Tools.
2017: Die Prinzipien des Chaos Engineering werden veröffentlicht und bieten einen formalen Rahmen für die Durchführung von Chaos-Experimenten in der gesamten Branche.
2019-2023: Weitverbreitete Adoption in Branchen jenseits der Technologie, wobei Chaos Engineering zu einer wesentlichen Praxis für Organisationen wird, die sich auf Zuverlässigkeit und Widerstandsfähigkeit konzentrieren.
Bemerkenswert an dieser Zeitlinie ist, wie sich Chaos Testing von Netflix‘ spezifischen Bedürfnissen zu einer universellen Praxis entwickelt hat. Die Methodik hat sich vom zufälligen Beenden von Servern zu einer ausgeklügelten Disziplin mit formalen Prinzipien, dedizierten Tools und weitverbreiteter Adoption entwickelt.
Vorteile und Grenzen des Chaos Testing
Beim Chaos Testing geht es darum, sich auf das Unvermeidliche vorzubereiten. In komplexen, verteilten Systemen sind Ausfälle keine Frage des ob, sondern des wann. Was Chaos Testing tut, ist, das Drehbuch umzudrehen: Anstatt zu warten, bis Dinge in der Produktion schief gehen, simulieren Sie Ausfälle zu Ihren eigenen Bedingungen, um zu sehen, wie Ihr System reagiert.
Einer der größten Vorteile ist Widerstandsfähigkeit. Wenn Sie routinemäßig Fehler injizieren und die Reaktion überwachen, entwickelt sich Ihr System natürlich zu einem fehlertoleranten System. Unternehmen wie Amazon und Netflix haben dem Chaos Testing die Verhinderung von groß angelegten Ausfällen zugeschrieben, die sonst unbemerkt geblieben wären. Es schärft auch die Instinkte Ihres Teams.
Teams, die regelmäßig Chaos-Experimente durchführen, erholen sich schneller von realen Vorfällen, weil sie bereits unter kontrollierten Bedingungen dort waren. Das Ergebnis? Weniger Ausfallzeiten, reibungslosere Benutzererfahrungen und höheres Vertrauen über Technik und Betrieb hinweg. Es verändert sogar Ihre Kultur: Anstatt Fehler zu fürchten, beginnen Sie, Systeme zu entwerfen, die sie erwarten und damit umgehen.
Das gesagt, ist Chaos Testing nicht ohne Einschränkungen. Wenn Sie es ohne angemessene Leitplanken durchführen, kann es echten Schaden anrichten. Schlecht geplante Experimente könnten Systeme zum Absturz bringen oder Benutzer beeinträchtigen, wenn sie nicht korrekt isoliert sind. Es gibt auch Kosten – das Einrichten sicherer Umgebungen, Überwachungstools und das Erstellen realistischer Szenarien erfordert Zeit und Ressourcen. Und obwohl die Idee an Popularität gewinnt, ist nicht jedes Team bereit, absichtlich Fehler einzuführen; es kann auf Widerstand von denen stoßen, die mit dem Ansatz nicht vertraut sind. Wie jede Methode funktioniert es am besten, wenn es neben anderen Teststrategien verwendet wird, nicht anstelle von ihnen.
Zusammengefasst:
Vorteile:
Baut Widerstandsfähigkeit auf
Verbessert die Erholungsgeschwindigkeit
Nachteile:
Erfordert Planung
Ist nicht risikofrei
Als Nächstes betrachten wir, was Sie mit Chaos Testing erreichen wollen und erklären es aus verschiedenen Perspektiven.
Ziele des Chaos Testing
Sobald Sie den Wert des Chaos Testing verstanden haben, ist der nächste Schritt, sich darüber klar zu werden, was Sie eigentlich erreichen wollen. Es geht nicht darum, Störungen um ihrer selbst willen zu verursachen. Es geht mehr darum, Schwachstellen aufzudecken, bevor sie Sie überraschen. Diese Ziele helfen dabei, Chaos-Experimente so zu lenken, dass sie fokussiert, sicher und die Mühe wert sind:
Systemwiderstandsfähigkeit verifizieren, indem bestätigt wird, dass Anwendungen Komponentenausfälle ohne vollständigen Systemzusammenbruch überstehen können
Single Points of Failure identifizieren, die bei Fehlfunktion das gesamte System zum Absturz bringen könnten
Wiederherstellungsmechanismen testen, um sicherzustellen, dass automatisches Failover, Wiederholungsversuche und Circuit Breaker wie vorgesehen funktionieren
Überwachungs- und Alarmsysteme validieren, die Fehlerbedingungen korrekt erfassen sollen
Organisatorisches Vertrauen aufbauen im Umgang mit unerwarteten Vorfällen
Die mittlere Wiederherstellungszeit (MTTR) verbessern, indem regelmäßig Ausfallszenarien geübt werden
Disaster-Recovery-Verfahren in realistischen Szenarien testen
Elegante Serviceabstufung verifizieren, wenn Abhängigkeiten nicht verfügbar sind
Versteckte Systemabhängigkeiten entdecken, die im Normalbetrieb möglicherweise nicht offensichtlich sind
Leistung unter Teilausfallbedingungen bewerten, um sicherzustellen, dass SLAs immer noch eingehalten werden können
Kommunikationskanäle stärken, die während der Vorfallsreaktion verwendet werden
Lastausgleich und automatische Skalierungsfähigkeiten während Teilausfällen testen
Diese Ziele im Auge zu behalten, hilft Ihnen, Experimente zu entwerfen, die echte Schwachstellen finden, ohne unnötiges Risiko einzuführen. Aber genauso wichtig wie was Sie testen ist wie Sie es angehen. Betrachten wir die Prinzipien, die Chaos Testing kontrolliert, sicher und bedeutungsvoll halten.
Die Prinzipien des Chaos Testing, oder eine Anleitung zur Durchführung
Chaos Testing funktioniert am besten, wenn es von einem klaren, disziplinierten Ansatz geleitet wird. Diese Prinzipien helfen Teams, aussagekräftige Experimente durchzuführen, ohne unnötige Störungen zu riskieren. Befolgen Sie diese Prinzipien, und Sie werden bei Ihren Chaos Testing-Bemühungen erfolgreich sein.
Definieren Sie das Normalverhalten: Beginnen Sie mit einer klaren Baseline. Identifizieren Sie, wie normale Systemleistung aussieht: Antwortzeiten, Fehlerraten oder wichtige Geschäftsmetriken. Dies gibt Ihnen einen Referenzpunkt zur Messung der Auswirkungen Ihres Tests.
Bilden Sie eine klare Hypothese: Machen Sie Ihre Erwartungen explizit. Wenn ein Dienst ausfällt, wie sollte das System reagieren? Das Aufschreiben hält den Test fokussiert und ermöglicht es Ihnen, den Erfolg objektiv zu messen.
Simulieren Sie reale Ausfälle: Wählen Sie Szenarien, die tatsächlich in der Produktion auftreten; Dinge wie Serverabstürze, Latenzspitzen oder Abhängigkeitsausfälle. Je näher Ihr Test an der Realität ist, desto wertvoller das Ergebnis.
Testen Sie in der Produktion (vorsichtig): Staging-Umgebungen verhalten sich selten wie die echte Sache. Führen Sie, wenn möglich, Experimente in der Produktion mit Leitplanken durch. Begrenzen Sie die Verkehrsexposition, isolieren Sie den Test und überwachen Sie genau.
Minimieren Sie den Auswirkungsradius: Fangen Sie klein an. Zielen Sie auf eine einzelne Instanz, ein kleines Verkehrssegment oder einen risikoarmen Dienst. Erweitern Sie den Umfang allmählich, während Sie Vertrauen in die Systemreaktion aufbauen.
Automatisieren Sie und führen Sie regelmäßig durch: Einmalige Chaostests reichen nicht aus. Wenden Sie Testautomatisierung an und führen Sie sie häufig durch, um Regressionen zu erkennen und mit Systemänderungen Schritt zu halten.
Messen Sie System- und Geschäftsauswirkungen: Hören Sie nicht bei CPU- oder Latenzmetriken auf. Verfolgen Sie, wie Vorfälle Benutzer, Transaktionen oder andere wichtige Geschäftsfunktionen beeinflussen. Das ist es, was wirklich zählt.
Schließen Sie einen Notausschalter ein: Haben Sie immer eine schnelle Möglichkeit, das Experiment zu stoppen. Wenn die Dinge außer Kontrolle geraten, müssen Sie sich schnell erholen können, ohne zu improvisieren.
Bei der Erforschung der Prinzipien des Chaos Testing fragen Sie sich vielleicht, wie Sie diese komplexen Testszenarien effektiv neben Ihren regulären Testaktivitäten verwalten können. Hier wird ein robustes Testmanagementsystem unschätzbar. aqua cloud bietet eine zentralisierte Plattform zur Organisation sowohl Ihrer traditionellen Testfälle als auch Chaos-Experimente mit vollständiger Nachverfolgbarkeit. Mit KI-gesteuerten, superschnellen Testgenerierungsfunktionen können Sie schnell umfassende Testszenarien erstellen, die die Widerstandsfähigkeit Ihres Systems unter verschiedenen Ausfallbedingungen überprüfen. aquas anpassbare Dashboards geben Stakeholdern Echtzeit-Einblick in den Testfortschritt, während die detaillierten Berichtsfunktionen helfen, Muster im Systemverhalten während Chaos-Experimenten zu identifizieren. Durch die Aufbewahrung aller Testaktivitäten, einschließlich Chaos Testing, an einem Ort können Sie eine vollständige Testabdeckung gewährleisten und gleichzeitig klare Verbindungen zwischen Anforderungen, Tests und Defekten aufrechterhalten.
Erreichen Sie 100% Testabdeckung mit konsistenten Prozessen und umfassender Dokumentation
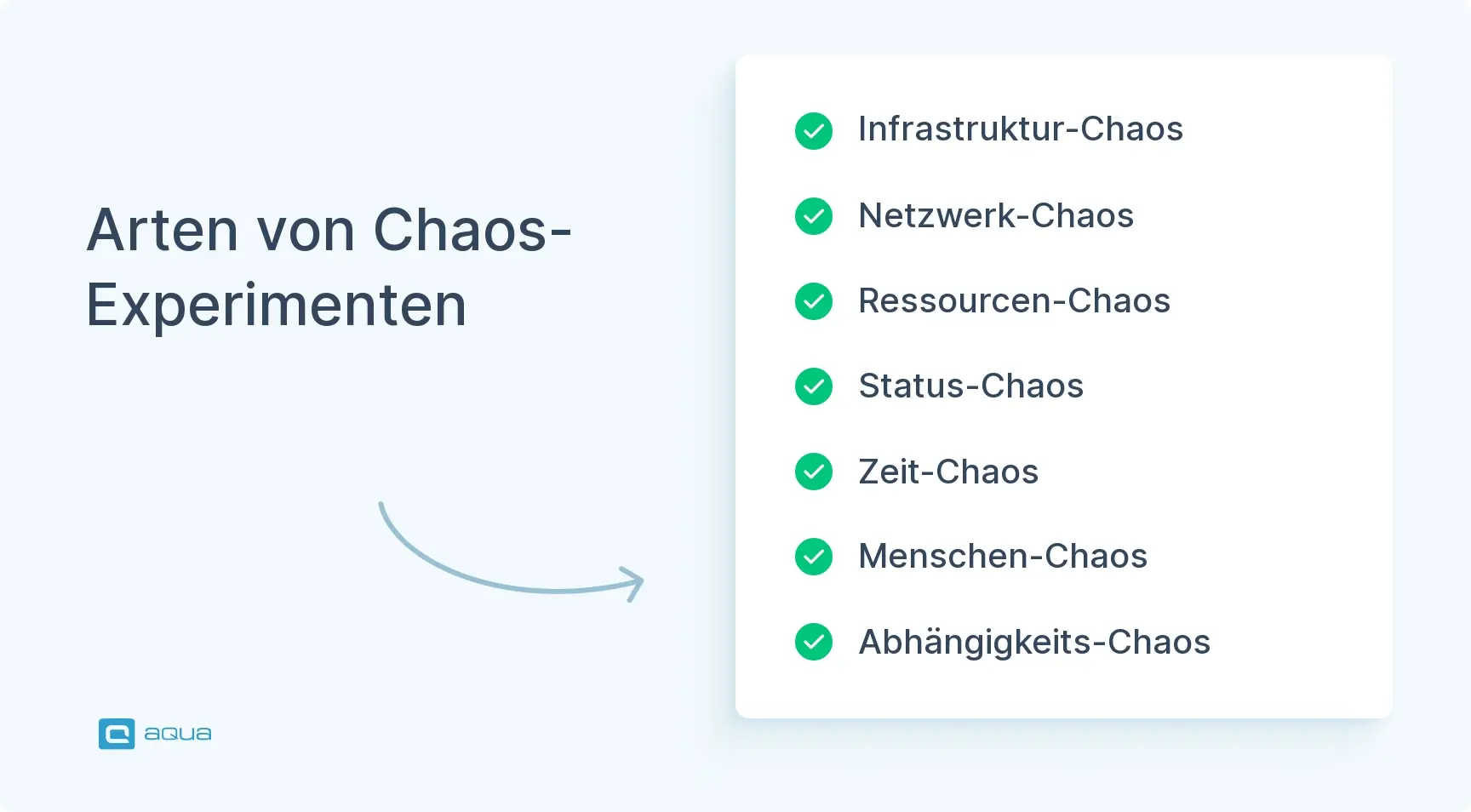
Chaos-Experimente kommen in vielen Formen, und jedes zielt auf eine andere Art von Schwachstelle ab. Je nach Architektur und Zielen Ihres Systems könnten Sie sich auf Infrastruktur, Daten, Abhängigkeiten oder sogar die Bereitschaft Ihres Teams konzentrieren. Hier sind einige der häufigsten (und nützlichsten) Arten von Chaos-Experimenten:
Infrastruktur-Chaos: Fahren Sie Server, Container oder Pods herunter, um zu testen, wie gut Ihr System mit einem plötzlichen Verlust umgeht. Beispielsweise können Sie einen Kubernetes-Pod zufällig beenden und beobachten, ob der Verkehr ordnungsgemäß umgeleitet wird.
Netzwerk-Chaos: Stören Sie das Netzwerk: Verwerfen Sie Pakete, fügen Sie Latenz hinzu oder erstellen Sie Service-Partitionen. Simulieren Sie ein Szenario, in dem zwei Dienste sich nicht erreichen können, und sehen Sie, ob das System sich elegant erholt.
Ressourcen-Chaos: Bringen Sie Ihre Server an die Grenze. Füllen Sie den Speicher, maximieren Sie die CPU-Auslastung oder erschöpfen Sie den Festplattenspeicher. Dies hilft dabei, zu enthüllen, wie sich Ihre App unter Druck verhält und ob sie elegant degradieren kann.
Zustands-Chaos: Manipulieren Sie die Daten. Modifizieren Sie Datensätze, injizieren Sie schlechte Eingaben oder simulieren Sie Datenbeschädigung. Das ist eine leistungsstarke Methode, um Validierungsregeln und Datenverarbeitungslogik zu testen.
Zeit-Chaos: Verschieben Sie die Systemuhr vor oder zurück. Einige Anwendungen verlassen sich auf zeitbasierte Logik für Dinge wie Token-Ablauf oder geplante Jobs; dies hilft Ihnen, versteckte zeitbezogene Fehler zu finden.
Anwendungs-Chaos: Injizieren Sie absichtlich Fehler in Ihren eigenen Code. Zwingen Sie eine API zum Scheitern, simulieren Sie Ausnahmen oder blockieren Sie den Zugriff auf interne Dienste. Dies ist eine gezielte Methode, um zu überprüfen, wie Ihre App mit internen Zusammenbrüchen umgeht.
Menschen-Chaos: Führen Sie einen Test durch, bei dem ein Schlüsselmitglied des Teams nicht verfügbar ist. Können andere einspringen? Können Vorfälle noch schnell gelöst werden? Dies hilft, Lücken in der Bereitschaftsabdeckung und Reaktionsdokumentation zu identifizieren.
Abhängigkeits-Chaos: Blockieren Sie Drittanbieterdienste wie Payment-Gateways, E-Mail-APIs oder externe Authentifizierung. Sie werden lernen, ob Ihr System mit fehlenden Abhängigkeiten umgehen kann oder ob es einfach abstürzt.
Verkehrs-Chaos: Lassen Sie die Last in die Höhe schnellen. Verdoppeln Sie den API-Traffic oder simulieren Sie, dass Tausende von Benutzern gleichzeitig einloggen. Dies zeigt, wie Ihr System skaliert — und ob die automatische Skalierung wie erwartet einsetzt.
Sicherheits-Chaos: Simulieren Sie Angriffe oder verdächtiges Verhalten. Versuchen Sie, Endpunkte zu überfluten oder unerwartete Eingaben zu erzwingen. Das Ziel ist, sowohl Ihre Verteidigungen als auch Ihre Überwachungssysteme zu testen.
Egal welchen Typ Sie wählen, das Ziel ist immer das gleiche: Schwachstellen unter kontrollierten Bedingungen erkennen, bevor sie in der Produktion zu echten Problemen werden.
Was Sie vor dem Start von Chaos Testing wissen sollten
Bevor Sie Fehler in Ihre Systeme einschleusen, selbst auf kontrollierte Weise, müssen Sie die Grundlagen schaffen. Chaos Testing ist nichts, in das man einfach so hineintaucht. Es erfordert Vorbereitung, Abstimmung und eine gesunde Portion Vorsicht.
Zunächst stellen Sie sicher, dass Ihr Monitoring-Setup solide ist. Sie benötigen vollständige Transparenz über die Systemgesundheit vor, während und nach dem Experiment. Wenn etwas schief geht, sollten Sie es in Echtzeit erkennen können, nicht erst, nachdem Kunden anfangen sich zu beschweren.
Jeder Test sollte mit einer klaren Hypothese beginnen. Was erwarten Sie, dass das System tut, wenn eine Datenbank ausfällt oder die Netzwerklatenz ansteigt? Diese Erwartung schriftlich festzuhalten, verwandelt Chaos in eine Lernchance, nicht nur in eine zufällige Störung.
Sie benötigen auch die Unterstützung sowohl der Führungsebene als auch Ihres Teams. Chaos Testing kann Menschen nervös machen, besonders wenn sie denken, es könnte einen echten Ausfall auslösen. Holen Sie im Voraus Unterstützung ein und machen Sie den Zweck klar: Es geht darum, Widerstandsfähigkeit aufzubauen, nicht Drama zu erzeugen.
Wenn Sie bereit sind, Ihr erstes Experiment durchzuführen, fangen Sie klein an. Begrenzen Sie den Auswirkungsradius auf eine einzelne Instanz, eine Testumgebung oder einen untergeordneten Dienst. Haben Sie Circuit Breaker an Ort und Stelle und stellen Sie sicher, dass es einen Rollback-Plan gibt, den Sie schnell ausführen können. Es geht nicht darum, paranoid zu sein, keine Sorge. Es geht darum, verantwortungsvoll zu sein.
Wählen Sie Ihren Zeitpunkt klug. Vermeiden Sie die Durchführung von Chaostests während Stoßzeiten oder unmittelbar vor größeren Produkteinführungen. Und stellen Sie sicher, dass Ihr Team weiß, wann Tests laufen und wie es reagieren soll, wenn die Dinge nicht wie erwartet verlaufen. Schulung zur Vorfallsreaktion sollte nicht optional sein; sie sollte eine Voraussetzung sein.
Dokumentieren Sie schließlich alles. Von der Hypothese über den Testaufbau bis zu dem, was tatsächlich passiert ist, behandeln Sie jedes Chaos-Experiment wie einen wissenschaftlichen Versuch. Diese Erkenntnisse sind es, die die gesamte Übung wertvoll machen und Ihnen helfen, es beim nächsten Mal besser zu machen.
Bei guter Vorbereitung wird sich Chaos Testing nicht wie rücksichtslose Störung anfühlen. Es wird sich wie selbstbewusstes, überlegtes Engineering anfühlen.
Anwendungsfälle und Beispiele für Chaos Testing
Chaos Testing hat sich weit über die Theorie hinaus entwickelt, und führende Technologieunternehmen verlassen sich darauf, ihre Systeme unter realen Belastungen zu validieren. Einer der am häufigsten zitierten Pioniere ist Netflix, das regelmäßig zufällige Microservice-Instanzen in der Produktion mit seinem „Chaos Monkey“-Tool beendet. Dies hilft sicherzustellen, dass andere Instanzen die Last übernehmen können, ohne die Benutzererfahrung zu beeinträchtigen, was eine kritische Fähigkeit auf einer Streaming-Plattform mit globalem Verkehr ist.
Intuit wendet Chaos Testing auf seine Kubernetes-Infrastruktur an und löscht zufällig Pods, um zu überprüfen, ob kritische Anwendungen wie seine Steuererklärungsplattform automatisch wiederhergestellt werden können. Diese Art von Resilienztest ist besonders wichtig während kritischer Zeiten wie Steuerfristen, wenn Verfügbarkeit nicht verhandelbar ist.
Im Finanzsektor simulieren Banken und Handelsplattformen oft Ausfälle der Primärdatenbank, um automatische Failover-Systeme zu testen. Das Ziel ist, Transaktionen reibungslos am Laufen zu halten, auch wenn die Kerninfrastruktur ausfällt, denn Ausfallzeiten im Finanzbereich bedeuten nicht nur Frustration; sie bedeuten verlorenes Geld und Vertrauen.
E-Commerce-Plattformen wie Amazon simulieren Ausfälle von Drittanbieterdiensten, wie Zahlungsabwickler-Ausfälle, während des Checkouts. Diese Tests überprüfen, ob Fallback-Mechanismen korrekt funktionieren und stellen sicher, dass Kunden ihre Käufe noch abschließen können, ohne von externen Dienstausfällen betroffen zu sein.
Selbst Cloud-Anbieter wie Microsoft haben Chaos Testing in größerem Maßstab übernommen. Azure-Teams führen regionsweite Ausfallsimulationen durch, um regionsübergreifende Redundanz und Servicekontinuität zu überprüfen, was beweist, dass Systeme Workloads nahtlos verlagern können, selbst bei massiven Störungen.
Diese Anwendungsfälle zeigen, dass Chaos Testing nicht nur für Randfälle ist – es wird zu einer kritischen Praxis für jedes Team, das Widerstandsfähigkeit, Stabilität und Kundenvertrauen schätzt.
Tools und Frameworks für Chaos Testing
Es gibt dedizierte Chaos Testing-Tools, die den Prozess rationalisieren. Die Wahl des richtigen Chaos Testing-Tools hängt von Ihrer Umgebung, Ihren Bedürfnissen und Ihrem Erfahrungsniveau ab. Hier ist ein Vergleich beliebter Optionen:
Tool
Am besten für
Hauptmerkmale
Einschränkungen
Umgebung
Chaos Monkey
Einstiegs-Servertests
Zufällige Instanzbeendigung, Open Source, Netflix-Herkunft
Begrenzte Fehlertypen, AWS-fokussiert
Cloud (hauptsächlich AWS)
Gremlin
Enterprise Chaos Testing
Breite Palette von Fehlertypen, Benutzerfreundliche UI, Sicherheitskontrollen
Kostenpflichtiges Abonnement, Einige Bereitstellungskomplexität
Multi-Cloud, On-Premises
LitmusChaos
Kubernetes-natives Chaos
Kubernetes-spezifische Ausfälle, Erweiterbar mit benutzerdefinierten Experimenten, CNCF-Projekt
Native AWS-Integration, Vordefinierte Vorlagen, Verwalteter Service
Nur AWS, Begrenzte Anpassung
Nur AWS
Pumba
Container-Netzwerk-Chaos
Einfache Einrichtung, Gut für Docker-Netzwerktests, Leichtgewichtig
Auf Docker beschränkt, Weniger Fehlermodi
Docker-Container
Chaos Toolkit
Framework-agnostisches Chaos
Erweiterbar über Plugins, Offene API-Spezifikation, Plattform-agnostisch
Mehr Setup erforderlich, Weniger intuitiv für Anfänger
Mehrere Plattformen
Bei der Auswahl eines Tools sollten Sie Folgendes berücksichtigen:
Ihre Infrastruktur (Cloud-Anbieter, Kubernetes usw.)
Arten von Ausfällen, die Sie simulieren müssen
Erforderliche Sicherheitsfunktionen
Integration mit Ihren bestehenden Überwachungstools
Teamexpertise und Lernkurve
Viele beginnen mit einfacheren Tools wie Chaos Monkey für grundlegende Instanzbeendigung und steigen auf umfassendere Plattformen wie Gremlin oder Chaos Mesh auf, wenn ihre Chaos-Praxis reift. Sie sollten nach Lösungen Ausschau halten, die Ihnen helfen, anspruchsvolle Experimente mit verschiedenen Graden an Kontrolle und Überwachungsfähigkeiten durchzuführen.
Was ist eine Chaos Testing-Pyramide?
Die Chaos Testing-Pyramide ist ein konzeptionelles Framework, das Chaos-Experimente über verschiedene Systemschichten organisiert, von der Infrastruktur bis zu Geschäftsprozessen. Ähnlich der traditionellen Testpyramide schlägt sie vor, wo Sie Ihre Chaos Testing-Bemühungen konzentrieren sollten.
An der Basis der Pyramide befindet sich Infrastruktur-Chaos – das Fundament, das Ihre Server, Netzwerke und Cloud-Ressourcen umfasst. Diese Ebene beinhaltet Experimente wie das Beenden von Instanzen, Einführen von Netzwerklatenz oder Simulieren von Ressourcenerschöpfung. Diese Tests sind typischerweise einfacher zu automatisieren und häufig durchzuführen.
Die mittlere Schicht besteht aus Anwendungs-Chaos, das sich auf Anwendungskomponenten wie Microservices, APIs und Datenbanken konzentriert. Experimente hier umfassen das Injizieren von Fehlern in spezifische Services, das Beschädigen von Daten oder das Auslösen von Fehlerzuständen in Anwendungen. Diese Tests erfordern ein tieferes Verständnis Ihrer Anwendungsarchitektur.
Ganz oben steht Geschäftsprozess-Chaos, das End-to-End-Workflows und User Journeys testet. Diese Experimente überprüfen, ob kritische Geschäftsfunktionen während Ausfällen weiterhin funktionsfähig bleiben. Beispielsweise die Sicherstellung, dass Kunden Käufe noch abschließen können, wenn der Empfehlungsdienst ausgefallen ist.
Beim Aufstieg in der Pyramide:
Experimente werden komplexer und spezifischer für Ihr Geschäft
Setup erfordert mehr teamübergreifende Koordination
Potenzielle Geschäftsauswirkungen nehmen zu
Die Häufigkeit der Testdurchführung nimmt typischerweise ab
Tests werden schwieriger zu automatisieren
Die Pyramide hilft Teams, ihre Chaos Testing-Bemühungen auszubalancieren, indem sie viele Infrastrukturtests häufig durchführen, während sie weniger, aber wirkungsvollere Geschäftsprozess-Experimente zu geplanten Intervallen durchführen.
Chaos Testing vs. Reguläres Testing
Um zu verstehen, wo Chaos Testing in Ihre QA-Strategie passt, hilft es, es direkt mit traditionellen Testmethoden zu vergleichen. Während beide darauf abzielen, die Softwarequalität zu verbessern, unterscheiden sich ihre Ziele, Denkweisen und Ausführungen erheblich.
Aspekt
Chaos Testing
Reguläres Testing
Zweck
Entdecken, wie Systeme ausfallen und Resilienz verbessern
Korrekte Funktionalität gegen Anforderungen verifizieren
Fokus
Systemverhalten während unerwarteter Ausfälle
Erwartetes Verhalten unter normalen Bedingungen
Ansatz
Proaktiv Fehler injizieren und Systemreaktion beobachten
Vordefinierte Testfälle mit erwarteten Ergebnissen ausführen
Umgebung
Idealerweise Produktion (mit Schutzmaßnahmen) oder produktionsähnlich
Üblicherweise Test- oder Staging-Umgebungen
Vorhersagbarkeit
Führt oft zufällige oder unerwartete Bedingungen ein
Normalerweise systemweit oder mehrere Komponenten betreffend
Oft fokussiert auf spezifische Komponenten oder Features
Denkweise
„Wie könnte dies auf unerwartete Weise brechen?“
„Funktioniert dies wie designed?“
Risikoniveau
Höheres Risiko (selbst mit Kontrollen)
Geringeres Risiko für Produktionssysteme
Chaos Testing ergänzt reguläres Testing, anstatt es zu ersetzen. Während traditionelles Testing überprüft, dass Ihr System korrekt funktioniert, stellt Chaos Testing sicher, dass es elegant versagt, wenn das Unerwartete eintritt, was die beiden Ansätze zu perfekten Partnern in einer umfassenden Teststrategie macht.
Chaos Testing vs. Load Testing
Chaos Testing wird auch häufig mit Load Testing verglichen, aber sie dienen unterschiedlichen Zwecken. Eines testet, wie Ihr System mit internen Störungen umgeht; das andere überprüft die Leistung unter externem Druck. Hier die Unterschiede:
Kann während des Normalbetriebs laufen (mit Schutzmaßnahmen)
Oft außerhalb der Hauptzeiten geplant
Hypothese
„Wird das System überleben, wenn X ausfällt?“
„Kann das System Y Benutzer gleichzeitig bewältigen?“
Ausfallmodus
Komponentenunverfügbarkeit oder -degradierung
Langsame Leistung oder vollständige Überlastung
Dauer
Oft kurz, kann aber verlängert werden
Typischerweise über längere Zeiträume aufrechterhalten
Tools
Chaos Monkey, Gremlin, LitmusChaos
JMeter, LoadRunner, Gatling
Schlüsselfrage
„Können wir Ausfälle überstehen?“
„Wie viele Benutzer können wir unterstützen?“
Während Load Testing Systeme an ihre Kapazitätsgrenzen bringt, bricht Chaos Testing bewusst Komponenten, um die Wiederherstellung zu testen. Für umfassende Resilienz sollten Sie beide Ansätze imChaos Performance-Testing kombinieren, um reale Szenarien zu simulieren, bei denen Ausfälle oft während Spitzenverkehrszeiten auftreten. Dies hilft Ihnen zu überprüfen, dass Ihr System Leistungsstandards aufrechterhalten kann, selbst wenn Komponenten unter Last ausfallen.
Wenn Sie einen Vergleich zwischen Resilienztests und Chaos Testing erstellen, sollten Sie verstehen, dass Resilienztests eine breitere Kategorie ist, die verschiedene Techniken zur Überprüfung der Fähigkeit eines Systems umfasst, Ausfällen standzuhalten und sich davon zu erholen. Chaos Testing ist ein spezifischer Ansatz innerhalb der Resilienztests, der sich auf das absichtliche Einbringen von Fehlern konzentriert, um die Systemreaktion zu testen.
Fazit
Denken Sie daran, dass effektives Chaos Testing klein anfängt. Beginnen Sie mit kontrollierten Experimenten in unkritischen Umgebungen, erstellen Sie eine klare Hypothese und erweitern Sie Ihre Chaos-Praxis schrittweise, während das Vertrauen wächst. Die Prinzipien, die wir skizziert haben – Definieren des stabilen Zustands, Minimieren des Auswirkungsradius, Ausführung in der Produktion wenn möglich und Automatisieren von Experimenten – bieten eine solide Grundlage. Auf diese Weise bauen Sie stärkere Systeme und fähigere Teams auf. Sind Sie bereit, etwas produktives Chaos auf Ihre Systeme loszulassen? Ihr zukünftiges Ich – das nicht diesen 3-Uhr-morgens-Anruf wegen eines Ausfalls erhält – wird es Ihnen danken.
Bereit, Chaos Testing in Ihrer Organisation zu implementieren, aber besorgt über die Komplexitätsverwaltung? aqua cloud rationalisiert den gesamten Prozess von der Planung Ihrer Chaos-Experimente bis zur Analyse der Ergebnisse. Unser zentralisiertes Testmanagementsystem hilft Ihnen, Ihre Steady-State-Metriken zu dokumentieren, Hypothesen zu verfolgen und detaillierte Beobachtungen aus jedem Experiment aufzuzeichnen. Mit aquas kollaborativen Funktionen bleibt Ihr gesamtes Team über bevorstehende Chaostests durch Benachrichtigungen und Kommentare informiert. Die leistungsstarken Berichtsfunktionen der Plattform machen es einfach, Muster über mehrere Chaos-Experimente hinweg zu identifizieren und verbesserte Systemresilienz gegenüber Stakeholdern zu demonstrieren. Und mit vollständiger Nachverfolgbarkeit zwischen Anforderungen, Tests und Defekten können Sie überprüfen, dass die Resilienz Ihres Systems sowohl technische als auch geschäftliche Ziele erfüllt. aquas robuste Auditprotokollierung bietet außerdem eine umfassende Dokumentation aller Testaktivitäten, was für regulierte Branchen wesentlich ist, in denen Resilienztests gründlich dokumentiert werden müssen.
Sparen Sie bis zu 40% Ihrer QA-Zeit, während Sie widerstandsfähigere Systeme mit vollständiger Testabdeckung aufbauen
Ein häufiges Beispiel ist das zufällige Beenden von Serverinstanzen in der Produktion, um zu überprüfen, ob Ihr Service weiterhin normal funktioniert. Netflix‘ Chaos Monkey macht genau das – es fährt zufällig Produktionsserver herunter, um sicherzustellen, dass ihr Streaming-Dienst durch Redundanz und automatische Wiederherstellung verfügbar bleibt.
Was ist der Unterschied zwischen Chaos Testing und Stress Testing?
Stress Testing bringt ein System durch extreme Lasten an seine Grenzen, um Schwachstellen zu finden, während Chaos Testing absichtlich Komponenten zerstört, um Resilienz zu testen. Stress Testing fragt „Wie viel kann das System bewältigen?“, während Chaos Testing fragt, „Was passiert, wenn Teile des Systems ausfallen?“
Warum führen wir Chaos Testing durch?
Wir führen Chaos Testing durch, um proaktiv Schwachstellen in unseren Systemen zu entdecken, bevor sie reale Ausfälle verursachen. Durch das absichtliche Injizieren von Fehlern in kontrollierten Umgebungen können Teams widerstandsfähigere Systeme aufbauen, Wiederherstellungsverfahren verbessern und Vertrauen im Umgang mit unerwarteten Vorfällen entwickeln.
Welche vier Schritte müssen beim Chaos Testing durchgeführt werden?
Die vier wesentlichen Schritte sind: 1) Definieren Sie das normale „Steady State“-Verhalten des Systems, 2) Bilden Sie eine Hypothese darüber, wie das System auf einen bestimmten Fehler reagieren wird, 3) Führen Sie ein Experiment durch, das diesen Fehler einführt, während Sie die Systemreaktion überwachen, und 4) Analysieren Sie die Ergebnisse und nehmen Sie Verbesserungen vor, um entdeckte Schwachstellen zu beheben.
Was sind die Prinzipien des Chaos Testing?
Die Kernprinzipien umfassen: Definition des Steady-State-Verhaltens, Bildung einer Hypothese, Minimierung des Auswirkungsradius, Durchführung von Experimenten in der Produktion (wenn möglich), Automatisierung von Experimenten und Bereitstellung eines Notausschalters, um Experimente zu stoppen, wenn sie unerwarteten Schaden verursachen. Diese Prinzipien stellen sicher, dass Chaos Testing als kontrollierter, wissenschaftlicher Prozess durchgeführt wird und nicht als zufällige Zerstörung.
Beginnen Sie Ihre Arbeit nicht mit gewöhnlichen E-Mails: Fügen Sie eine gesunde Dosis an aufschlussreichen Softwaretest-Tipps von unseren QS-Experten hinzu.
Werden Sie Teil unserer Community von begeisterten Experten! Erhalten Sie neue Beiträge aus dem aqua-Blog direkt in Ihre Inbox. QS-Trends, Übersichten über Diskussionen in der Community, aufschlussreiche Tipps — Sie werden es lieben!
Wir sind dem Schutz Ihrer Privatsphäre verpflichtet. Aqua verwendet die von Ihnen zur Verfügung gestellten Informationen, um Sie über unsere relevanten Inhalte, Produkte und Dienstleistungen zu informieren. Diese Mitteilungen können Sie jederzeit wieder abbestellen. Weitere Informationen finden Sie in unserer Datenschutzrichtlinie.
X
🤖 Neue spannende Updates sind jetzt für den aqua KI Assistenten verfügbar! 🎉
Wir verwenden Cookies und Dienste von Drittanbietern, die Informationen auf dem Endgerät unserer Besucher speichern oder abrufen. Diese Daten werden verarbeitet und genutzt, um unsere Website zu optimieren und kontinuierlich zu verbessern. Für die Speicherung, den Abruf und die Verarbeitung dieser Daten benötigen wir Ihre Zustimmung. Sie können Ihre Zustimmung jederzeit widerrufen, indem Sie auf einen Link im unteren Bereich unserer Website klicken. Weitere Informationen finden Sie in unserer Datenschutzrichtlinie
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen werden die nach Bedarf kategorisierten Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der Grundfunktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, die uns helfen, zu analysieren und zu verstehen, wie Sie diese Website nutzen. Diesecookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.













































{kind=link}