Regressionstest Checkliste: Schritt-für-Schritt-Anleitung für QA-Teams
Sie implementieren an einem Dienstag eine kleine Fehlerbehebung. Am Mittwochmorgen können sich Benutzer nicht mehr anmelden. Die Korrektur betraf das Payment-Gateway. Der Login hat nichts mit dem Payment-Gateway zu tun. Außer dass er es doch tut, irgendwo, auf eine Weise, die niemand dokumentiert hat. Genau dieses Problem sollen [Regressionstests](https://aqua-cloud.io/de/regression-testing/) lösen. Nicht mit Hoffnung, sondern mit einer Checkliste, die Sie zwingt, vor jedem Release über das Offensichtliche hinauszuschauen.
Regressionstests überprüfen, dass neue Codeänderungen keine zuvor funktionierende Funktionalität beeinträchtigen und dienen als Sicherheitsnetz bei Fehlerbehebungen, Feature-Ergänzungen, Code-Refactoring und Infrastrukturupdates.
Eine Regressionstest Checkliste identifiziert systematisch, welche Tests basierend auf Codeänderungen durchzuführen sind, gewährleistet konsistente Abdeckung über Teammitglieder hinweg und bewahrt Institutionswissen über anfällige Komponenten.
Effektive Regressionsstrategien priorisieren Testfälle nach Geschäftsauswirkungen, konzentrieren sich auf kritische Pfade, die bei Fehlfunktionen den Betrieb stoppen würden, Integrationspunkte zwischen Systemen und historisch problematische Module.
Der beste Ansatz kombiniert automatisierte Regressionstests für stabile, repetitive Funktionen mit gezieltem manuellen Testen für Hochrisikobereiche und komplexe Benutzerszenarien.
Proportionale Testreaktion ist entscheidend – die Testintensität sollte dem Risiko entsprechen, das jede Änderung mit sich bringt, anstatt bei jedem Update alles zu testen.
Ohne einen strukturierten Regressionstest-Ansatz spielen Sie bei jeder Bereitstellung im Wesentlichen Glücksspiel – diese kleine UI-Korrektur könnte still Ihr Zahlungssystem beschädigen. Erfahren Sie, wie Sie eine Regressionsteststrategie aufbauen, die tatsächlich für Ihr Team funktioniert 👇
Was ist Regressionstest
Regressionstest ist die Praxis, Tests für zuvor funktionierende Funktionen nach Codeänderungen erneut auszuführen. Das Ziel ist, Nebenwirkungen zu entdecken, bevor es die Benutzer tun.
Sie benötigen Regressionstests nach Fehlerbehebungen, Feature-Ergänzungen, Refactoring, Infrastrukturupdates und Integrationen von Drittanbietern. Ein Sicherheits-Patch in Ihrem Authentifizierungsmodul sollte nicht die Passwort-Zurücksetzung beeinträchtigen. Ein neuer Checkout-Schritt sollte nicht still die Versandberechnungen beschädigen. Eine Datenbankabfrage-Optimierung sollte nicht Ihr Audit-Log außer Betrieb setzen. Dies sind keine Hypothesen. Es sind die Arten von Vorfällen, die Regressionstests verhindern sollen.
Der Unterschied zwischen Teams, die diese Probleme intern entdecken, und Teams, die davon durch Benutzer erfahren, ist nicht Glück. Es ist Prozess.
Sie wissen, wie wichtig es ist, Regressionsfehler zu erkennen, bevor sie in die Produktion gelangen, aber die Aufrechterhaltung eines umfassenden Regressionstestprozesses kann zeitaufwändig sein und zu menschlichen Fehlern führen. Hier transformiert ein modernes Testmanagementsystem wie aqua cloud Ihren Ansatz. Mit aqua können Sie alle Ihre Testartefakte in einem einzigen Repository zentralisieren, einfach wiederverwendbare Testkomponenten für Ihre Regressionssuite erstellen und sicherstellen, dass nichts Kritisches übersehen wird. Die KI-gestützten Testfallerstellungsfunktionen der Plattform, angetrieben durch aquas domänentrainierte Copilot KI mit RAG-Grounding, können automatisch Regressionstestfälle basierend auf Ihren Anforderungen und vorhandener Dokumentation vorschlagen und sparen Ihrem Team unzählige Stunden manueller Arbeit bei gleichzeitig besserer Abdeckung. Im Gegensatz zu generischen KI-Tools versteht Copilot KI Ihren spezifischen Projektkontext und erstellt Testfälle, die die Sprache Ihres Teams sprechen und die einzigartigen Risikobereiche Ihrer Anwendung adressieren.
Sparen Sie bis zu 97% Ihrer Testzeit mit einer Regressionssuite, die Ihr Projekt wirklich versteht
Warum eine Regressionstest Checkliste für Senior-QA-Teams wichtig ist
Wenn Sie lange genug im QA-Bereich tätig sind, haben Sie dies erlebt: Ein Tester führt Regressionstests für einen Build durch, markiert ihn als grün, und trotzdem tritt in der Produktion ein Fehler auf. Nicht weil der Tester nachlässig war, sondern weil es keine gemeinsame Definition gab, was Regressionsabdeckung für dieses Release tatsächlich bedeutet.
Eine Regressionstest Checkliste löst drei Probleme, die Erfahrung allein nicht lösen kann.
Konsistenz über Personen hinweg. Wenn Ihr Senior-QA Regressionstests durchführt, deckt er dasselbe Gebiet ab wie wenn Ihr neuester Mitarbeiter dies tut. Nicht weil sie das gleiche institutionelle Wissen haben, sondern weil die Checkliste dieses Wissen explizit erfasst.
Abdeckung des nicht Offensichtlichen. Vor sechs Monaten haben Sie entdeckt, dass die Aktualisierung der E-Mail-Template-Bibliothek die Benachrichtigungseinstellungen beschädigt hat. Wer erinnert sich ohne Checkliste an diese Verbindung, wenn Sie wieder Bibliotheken aktualisieren? Die Checkliste tut es. Sie verwandelt hart erlernte Lektionen in dauerhafte Leitplanken.
Prüfpfad. Wenn etwas in der Produktion fehlschlägt, müssen Sie wissen, was getestet wurde und was nicht. Eine ausgefüllte Checkliste ist Ihr Beweis. Ein undokumentiertes „Wir haben Regressionstests durchgeführt“ ist es nicht.
Regressionstest Checkliste Vorlage
Verwenden Sie dies als Ausgangsbasis. Passen Sie sie an Ihren Stack, Ihre Release-Kadenz und Ihr Risikoprofil an.
Vorbereitung vor Regression
[ ] Identifizieren aller Codeänderungen in diesem Release und Dokumentation der betroffenen Module
[ ] Überprüfung früherer Regressionsergebnisse für betroffene Bereiche
[ ] Bestätigung, dass die Testumgebung der Produktionskonfiguration entspricht
[ ] Überprüfung, dass Testdaten aktuell und vollständig sind
[ ] Bestätigung, dass alle Unit- und Integrationstests vor Beginn der Regression bestanden werden
[ ] Identifizierung, welche Testfälle automatisiert sind und welche manuell ausgeführt werden müssen
[ ] Zuweisung von Verantwortlichkeiten für jeden Testbereich
[ ] Passwort-Zurücksetzung und Account-Recovery-Abläufe
[ ] Benutzerregistrierung und E-Mail-Verifizierung
[ ] Rollenbasierte Zugriffskontrolle für alle Berechtigungsstufen
[ ] Kerngeschäftsabläufe von Anfang bis Ende
[ ] Datenerstellung, -bearbeitung und -löschung über alle primären Entitäten hinweg
[ ] Suche und Filterung über alle primären Module hinweg
[ ] Paginierungs- und Sortierungsverhalten
Integrationspunkte
Integrationspunkte sind der Ort, an dem sich Regressionsfehler am zuverlässigsten verstecken. Decken Sie jeden Punkt ab, an dem zwei Systeme miteinander kommunizieren.
[ ] API-Endpunkte, die von Codeänderungen betroffen sind
[ ] Integrationen von Drittanbietern (Zahlungs-Gateways, E-Mail-Anbieter, Analyse-Tools)
[ ] Datenbanktransaktionen für modifizierte Abfragen oder Schemaänderungen
[ ] Datensynchronisation zwischen integrierten Modulen
UI und Cross-Browser
[ ] Wichtige Benutzerabläufe werden in unterstützten Browsern korrekt dargestellt
[ ] Responsives Verhalten auf mobilen und Tablet-Breakpoints
[ ] Formularvalidierungsmeldungen werden korrekt angezeigt
[ ] Fehlerzustände zeigen angemessene Meldungen ohne Systemdetails preiszugeben
[ ] Navigation und Routing funktionieren nach Änderungen korrekt
[ ] Zugänglichkeitsanforderungen werden für modifizierte Komponenten beibehalten
Leistungsregression
Eine Funktion kann Funktionstests bestehen und trotzdem Regressionen aufweisen. Langsamere Reaktionszeiten unter derselben Last ist eine Regression.
[ ] Seitenladezeiten innerhalb definierter Schwellenwerte für modifizierte Seiten
[ ] API-Antwortzeiten innerhalb der SLA für betroffene Endpunkte
[ ] Baseline für Datenbankabfrageleistung wird beibehalten
[ ] Speicherverbrauch stabil unter normaler Last
[ ] Keine neuen N+1-Abfragemuster eingeführt
Sicherheitsregression
[ ] Authentifizierung kann auf modifizierten Endpunkten nicht umgangen werden
[ ] Autorisierungsprüfungen für rolleneingeschränkte Funktionen durchgesetzt
[ ] Eingabevalidierung bei allen modifizierten Formularfeldern vorhanden
[ ] Sensible Daten werden nicht in API-Antworten oder Logs offengelegt
[ ] CSRF-Schutz bei modifizierten Formularen intakt
Datenintegrität
[ ] Datenmigrationen korrekt ausgeführt ohne Datenverlust
[ ] Berechnungen und Aggregationen liefern korrekte Ergebnisse
[ ] Reporting- und Exportfunktionen erzeugen genaue Ausgaben
[ ] Audit-Logs erfassen alle erforderlichen Aktionen
[ ] Kaskadierende Operationen (Löschen, Aktualisieren) verhalten sich wie erwartet
Abnahme nach Regression
[ ] Alle kritischen und hochprioritären Testfälle bestanden
[ ] Bekannte Fehler dokumentiert mit Risikobewertung
[tml] Automatisierungssuite aktualisiert, um neu entdeckte Szenarien abzudecken
[ ] Regressionsergebnisse protokolliert und priorisiert
[ ] QA-Freigabe dokumentiert mit Abdeckungszusammenfassung
Wie man eine skalierbare Regressionsteststrategie aufbaut
Jeden Test bei jedem Build auszuführen ist keine Strategie. Es ist ein Engpass. Senior-QA-Teams denken in Stufen.
Stufe eins: bei jedem Build ausführen. Ihr kritischer Pfad. Authentifizierung, Kerngeschäftsabläufe, Zahlungsabwicklung, Datenintegritätsprüfungen. Wenn diese fehlschlagen, wird das Release nicht ausgeliefert. Automatisieren Sie so viel wie möglich von dieser Stufe.
Stufe zwei: vor jedem Release ausführen. Wichtige, aber nicht unmittelbar kritische Funktionalität. Berichtswesen, Admin-Tools, sekundäre Abläufe, Integrations-Randfälle. Diese erhalten vollständige Abdeckung, bevor eine Version veröffentlicht wird.
Stufe drei: bei größeren Releases oder vierteljährlich ausführen. Bereiche mit niedrigerem Risiko, selten genutzte Funktionen, Legacy-Funktionalität mit stabilem Code. Diese benötigen immer noch Abdeckung, aber nicht bei jedem Zyklus.
Die Auslöser sind genauso wichtig wie die Stufen. Ein Hotfix für einen UI-Tippfehler rechtfertigt Smoke-Tests des betroffenen Bereichs plus seiner unmittelbaren Abhängigkeiten. Eine Datenbankschemaänderung erfordert vollständige Regression über alle Module, die diese Daten berühren. Ein Upgrade einer Drittanbieter-Bibliothek erfordert Regression über jeden Integrationspunkt, den diese Bibliothek berührt. Passen Sie die Testintensität dem durch die Änderung eingeführten Risiko an, nicht einem festen Zeitplan.
KI-Regressionstests verändern, wie Teams mit der Testauswahl im großen Maßstab umgehen. Impact-Analysis-Tools, die automatisch identifizieren, welche Testfälle für eine bestimmte Codeänderung relevant sind, reduzieren den manuellen Aufwand der Stufenzuweisung und halten die Abdeckung genau, während sich die Codebasis weiterentwickelt.
Auswahl von Testfällen für Ihre Regressionssuite
Die Qualität Ihrer Regressionssuite hängt von den Auswahlkriterien ab. Mehr Tests sind nicht besser. Relevantere Tests sind besser.
Beginnen Sie mit historischen Fehlerdaten. Welche Module brechen am häufigsten? Welche Integrationen haben Produktionsvorfälle verursacht? Diese erhalten dauerhafte Plätze in Ihrer Stufe-eins-Suite, unabhängig davon, wie stabil sie im Moment erscheinen. Stabilität ist vorübergehend. Abdeckung ist eine Richtlinie.
Priorisieren Sie Integrationspunkte vor isolierten Einheiten. Unit-Tests fangen isolierte Logikfehler ab. Regressionstests fangen die Fehler ab, die auftreten, wenn Systeme interagieren. Konzentrieren Sie Ihre Regressionsabdeckung auf API-Verträge, gemeinsam genutzte Datenmodelle und modulübergreifende Arbeitsabläufe. Dort leben die Nebenwirkungen.
Decken Sie die Fehlerbehandlung explizit ab. Happy-Path-Tests sind notwendig, aber nicht ausreichend. Ihre Regressionssuite sollte überprüfen, ob die Anwendung bei schlechten Eingaben, fehlenden Abhängigkeiten und unerwarteten Zuständen elegant fehlschlägt. Diese Szenarien sind oft die ersten, die bei Codeänderungen brechen, und die letzten, die getestet werden.
Beziehen Sie Leistungsbaselines für modifizierte Bereiche ein. Eine Abfrage, die vor einer Änderung in 50 ms läuft und danach in 800 ms, ist eine Regression, auch wenn sie korrekte Ergebnisse liefert. Leistungsregression ist echte Regression und gehört in die Checkliste.
Gutes Management der Regressionstest-Suite bedeutet, Ihre Suite regelmäßig zu überprüfen und zu beschneiden. Tests, die nie fehlschlagen und stabilen, unveränderten Code abdecken, können Kandidaten für eine niedrigere Stufe sein. Tests, die Probleme auf Produktionsebene abfangen, verdienen Investitionen in Zuverlässigkeit und Wartung.
Regressionstest in Agile-Umgebungen
In agilen Teams, die in jedem Sprint liefern, kann Regression keine Phase sein. Sie muss kontinuierlich sein.
Der praktische Ansatz ist eine geschichtete Automatisierungsstrategie. Schnelle automatisierte Smoke-Tests laufen bei jedem Commit. Eine breitere automatisierte Regressionssuite läuft bei jedem Build, der die Smoke-Tests besteht. Manuelle Regression zielt auf die Hochrisiko- und Hochkomplexitätsbereiche, die Automatisierung nicht gut abdeckt, typischerweise UI-lastige Abläufe und explorative Validierung neuerer Änderungen.
Sprint-Retrospektiven sollten Regressionsergebnisse beinhalten. Wenn dasselbe Modul immer wieder Regressionsfehler generiert, ist das ein Signal über die Codequalität oder Testabdeckung in diesem Bereich, nicht nur ein Testproblem. Regressionstest in Agile funktioniert am besten, wenn Entwickler und QA Regressionsergebnisse als gemeinsame Information behandeln, anstatt als Übergabeergebnis.
Die Definition of Done sollte die Regressionsfreigabe für jede Story umfassen, die bestehende Funktionalität modifiziert. Das ist keine Bürokratie. Es ist der Unterschied zwischen dem Entdecken einer Regression in dem Sprint, in dem sie eingeführt wurde, und dem Entdecken drei Sprints später, wenn die Spur kalt geworden ist.
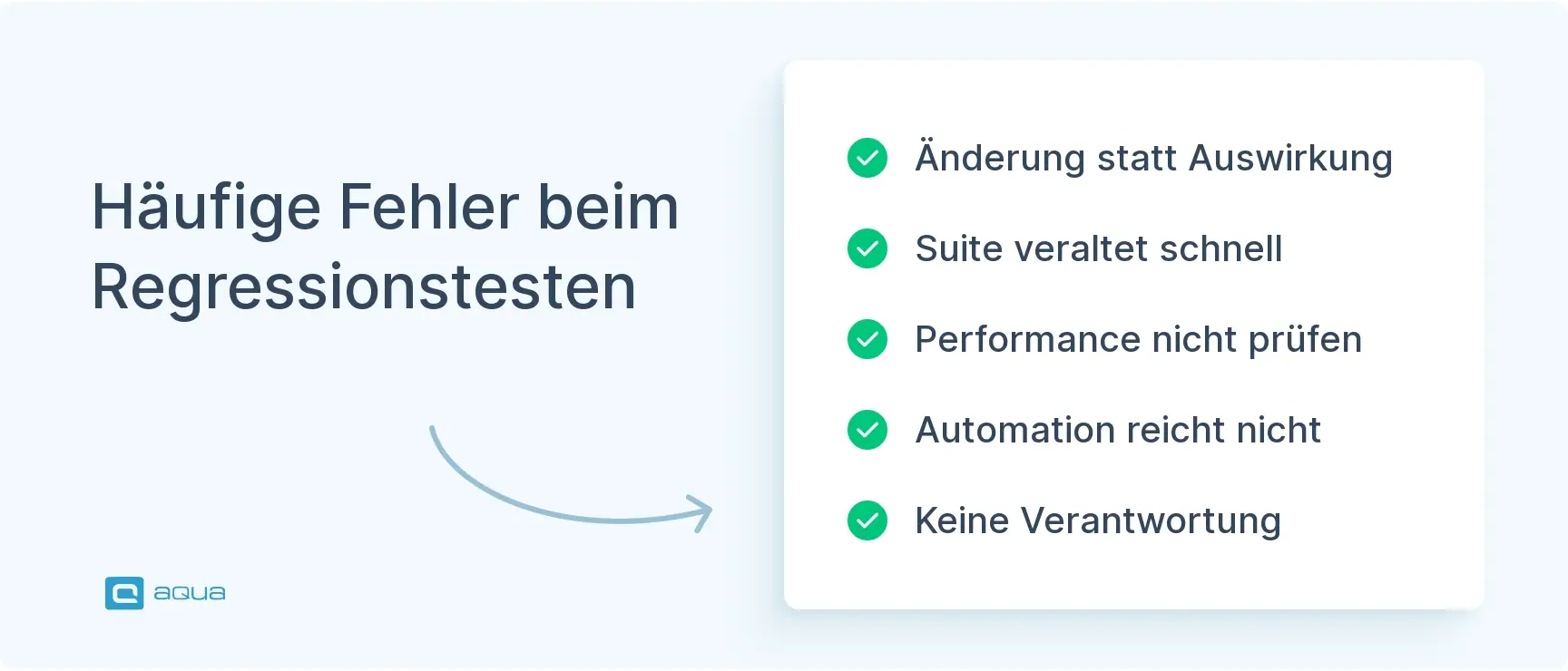
Häufige Regressionstest-Fehler, die Senior-QAs machen
Selbst erfahrene Teams fallen in Muster, die die Regressionseffektivität einschränken.
Die Änderung testen, nicht die Auswirkung. Der häufigste Fehler. Sie beheben einen Fehler in Modul A und testen Modul A. Aber Modul A teilt sich einen Dienst mit den Modulen B und C. Die Regressionstest Checkliste zwingt Sie, die Auswirkungen zu kartieren, nicht nur die Fehlerbehebung zu überprüfen.
Die Suite veralten lassen. Eine Regressionssuite, die seit sechs Monaten nicht überprüft wurde, deckt die gestrige Anwendung ab. Neue Funktionen, veraltete Abläufe und geänderte Geschäftslogik müssen alle in der Checkliste reflektiert werden. Mindestens vierteljährliche Überprüfungen.
Leistungsregression überspringen. Funktionale Korrektheit wird überprüft. Verschlechterung der Antwortzeit nicht. Bauen Sie Leistungsbaselines in Ihre Checkliste für jeden Bereich mit modifizierten Abfragen oder Datenverarbeitungslogik ein.
Automatisierungsabdeckung als Regressionsabdeckung behandeln. Automatisierte Tests laufen. Das bedeutet nicht, dass sie die richtigen Dinge abdecken. Überprüfen Sie, was Ihre automatisierte Suite tatsächlich validiert, nicht nur, welcher Prozentsatz der Tests besteht.
Keine Verantwortlichkeit für Checklistenelemente. Eine Checkliste ohne benannte Verantwortliche ist eine Wunschliste. Jeder Punkt braucht jemanden, der für den Abschluss und die Abnahme verantwortlich ist, bevor die Release-Gates geschlossen werden.
Der Aufbau und die Pflege einer effektiven Regressionstest Checkliste ist unerlässlich, aber nur die halbe Miete. Die richtige Testmanagement-Plattform kann Ihre Regressionsstrategie von gut zu hervorragend verbessern. aqua cloud bietet alles, was Sie benötigen, um Ihren Regressionstestprozess zu transformieren – von zentralisiertem Testvermögensmanagement und wiederverwendbaren Testkomponenten bis hin zu leistungsstarken Integrationen mit Jira, CI/CD-Pipelines und Automatisierungstools. Mit einer einzigartigen domänentrainierten Copilot KI können Sie umfassende Regressionstestfälle direkt aus Ihren Anforderungen und Projektdokumentationen generieren, die kontextuell relevant und auf Ihre spezifischen Testanforderungen abgestimmt sind. Die dynamischen Testszenarien der Plattform verweisen auf Kern-Testfälle ohne Duplizierung, was bedeutet, dass Sie einmal aktualisieren und Änderungen überall sehen können. Dieser Ansatz zum Regressionstest verbessert grundlegend die Qualität und reduziert gleichzeitig die kognitive Belastung Ihres Teams. Und mit anpassbaren Dashboards und automatisiertem Reporting haben Sie immer Einblick in Ihre Regressionsabdeckung, Ausführungshistorie und aufkommende Risikobereiche.
Erreichen Sie 100% Regressionsabdeckung mit KI-gestütztem Testmanagement, das sich an Ihre sich ändernde Codebasis anpasst
Eine Regressionstest Checkliste ist kein Prozess-Overhead. Sie ist das gemeinsame Gedächtnis Ihres Teams dafür, was bricht, was wichtig ist und was vor jedem Release überprüft werden muss. Bauen Sie sie um Ihr tatsächliches Risikoprofil herum auf, halten Sie sie aktuell und machen Sie die Abnahme explizit. Die Teams, die mit Vertrauen ausliefern, sind nicht diejenigen, die die meisten Tests durchführen. Es sind diejenigen, die die richtigen Tests konsistent durchführen, mit klarer Verantwortlichkeit und dokumentierten Ergebnissen. Beginnen Sie mit der hier vorgestellten Vorlage, passen Sie sie an Ihren Stack an und aktualisieren Sie sie jedes Mal, wenn die Produktion Ihnen etwas Neues beibringt.
Eine Regressionstest Checkliste ist ein strukturiertes Dokument, das genau definiert, was nach Codeänderungen überprüft werden muss, um zu bestätigen, dass zuvor funktionierende Funktionalität noch funktioniert. Sie umfasst die auszuführenden Testfälle, die zu überprüfenden Module, die zu kontrollierenden Integrationspunkte und die Abnahmekriterien, die vor dem Fortschreiten eines Releases erfüllt werden müssen. Der Unterschied zwischen einer Regressionstest Checkliste und einem allgemeinen Testplan ist die Spezifität. Die Checkliste ist an Ihre tatsächliche Anwendung, Ihre tatsächlichen Risikobereiche und Ihre tatsächliche Fehlerhistorie gebunden. Sie ist das gemeinsame Gedächtnis Ihres Teams dafür, was bricht und was jedes Mal überprüft werden muss, wenn sich etwas ändert. Ohne sie hängt die Regressionsabdeckung davon ab, wer die Tests an diesem Tag durchführt und woran er sich zufällig erinnert.
Was sollte in der Regressionstest Checkliste enthalten sein?
Eine solide Regressionstest Checkliste deckt sieben Bereiche ab. Kernfunktionalität einschließlich Authentifizierung, primäre Benutzerworkflows und Datenoperationen. Integrationspunkte, die jeden Ort abdecken, an dem zwei Systeme kommunizieren, API-Verträge, Drittanbieterdienste und Datenbanktransaktionen. UI- und Cross-Browser-Verhalten für modifizierte Komponenten. Leistungsbaselines für Bereiche mit geänderten Abfragen oder Datenverarbeitungslogik. Sicherheitsprüfungen, die bestätigen, dass Autorisierung und Eingabevalidierung auf modifizierten Endpunkten intakt sind. Datenintegritätsüberprüfung für Berechnungen, Exporte und Audit-Logs. Und ein Abschnitt zur Abnahme nach der Regression mit benannten Verantwortlichen und einer dokumentierten Abdeckungszusammenfassung. Die Tiefe jedes Abschnitts sollte das Risikoprofil Ihrer Anwendung widerspiegeln. Eine Vorlage für eine Checkliste für Regressionstests ist ein Ausgangspunkt, keine endgültige Antwort. Passen Sie sie basierend darauf an, was zuvor in der Produktion fehlgeschlagen ist und was die kritischsten Pfade Ihrer Anwendung tatsächlich sind.
Wie kann Automatisierung in eine Regressionstest Checkliste integriert werden?
Der effektivste Ansatz ist ein Schichtenmodell. Schnelle automatisierte Smoke-Tests laufen bei jedem Commit und decken die kritischsten Pfade ab. Eine breitere automatisierte Regressionssuite läuft bei jedem Build, der die Smoke-Tests besteht, und deckt Funktionalität der Stufe eins und zwei ab. Manuelle Regression zielt auf die Bereiche, die Automatisierung schlecht handhabt, typischerweise komplexe UI-Flows, explorative Validierung und Szenarien, die menschliches Urteilsvermögen erfordern. Ihre Regressionstest Checkliste sollte explizit markieren, welche Elemente automatisiert sind, welche manuell sind und welche beides benötigen. Dies verhindert die Annahme, dass eine bestandene automatisierte Suite einer vollständigen Regressionsabdeckung entspricht. KI-Regressionstests können auch bei der Auswirkungsanalyse helfen, indem sie automatisch identifizieren, welche Testfälle für eine bestimmte Codeänderung relevant sind, anstatt jedes Mal die vollständige Suite auszuführen. Für Teams, die Regressionstests in Agile-Sprints durchführen, ist Automatisierung, die in die CI-Pipeline integriert ist, das, was kontinuierliche Regression praktisch macht, ohne zum Engpass zu werden.
Welche häufigen Fallstricke sollten bei der Erstellung einer Regressionstest Checkliste vermieden werden?
Der schädlichste Fallstrick ist, den Umfang der Checkliste auf die Änderung statt auf ihre Auswirkung zu beschränken. Eine Korrektur in Modul A, das einen Dienst mit den Modulen B und C teilt, benötigt Regressionsabdeckung über alle drei, nicht nur das Modul, das berührt wurde. Zweitens, die Checkliste veralten zu lassen. Eine Checkliste, die widerspiegelt, wie die Anwendung vor sechs Monaten funktionierte, ist aktiv irreführend. Bauen Sie einen Überprüfungsrhythmus in Ihren Release-Prozess ein und aktualisieren Sie sie, wann immer Produktionsvorfälle ungedeckte Bereiche aufzeigen. Drittens, den Abschluss der Checkliste als binär zu behandeln. Elemente, die als erledigt markiert sind, ohne dokumentiertes Ergebnis, sagen Ihnen nichts Nützliches. Jeder Abschnitt sollte erfassen, was getestet wurde, was bestanden hat, was fehlgeschlagen ist und welches Risiko akzeptiert wurde. Viertens, Leistungsregression zu verpassen. Funktionale Korrektheit wird überprüft. Verschlechterung der Antwortzeit nach einer Abfrageänderung oft nicht. Beziehen Sie Leistungsbaselines für jeden Bereich mit modifizierter Datenverarbeitungslogik ein. Schließlich, vermeiden Sie Checklisten ohne benannte Verantwortliche. Jeder Punkt braucht jemanden, der verantwortlich ist. Gutes Management der Regressionstest-Suite hängt davon ab, dass Verantwortlichkeit explizit ist, nicht angenommen.
Beginnen Sie Ihre Arbeit nicht mit gewöhnlichen E-Mails: Fügen Sie eine gesunde Dosis an aufschlussreichen Softwaretest-Tipps von unseren QS-Experten hinzu.
Home » 'How to'-Leitfäden » Regressionstest Checkliste: Schritt-für-Schritt-Anleitung für QA-Teams
Lieben Sie das Testen genauso wie wir?
Werden Sie Teil unserer Community von begeisterten Experten! Erhalten Sie neue Beiträge aus dem aqua-Blog direkt in Ihre Inbox. QS-Trends, Übersichten über Diskussionen in der Community, aufschlussreiche Tipps — Sie werden es lieben!
Wir sind dem Schutz Ihrer Privatsphäre verpflichtet. Aqua verwendet die von Ihnen zur Verfügung gestellten Informationen, um Sie über unsere relevanten Inhalte, Produkte und Dienstleistungen zu informieren. Diese Mitteilungen können Sie jederzeit wieder abbestellen. Weitere Informationen finden Sie in unserer Datenschutzrichtlinie.
X
🤖 Neue spannende Updates sind jetzt für den aqua KI Assistenten verfügbar! 🎉