Testumgebungen in agilen Projekten: Der ultimative Leitfaden
Langsame Releases, Bugs in der Produktion und ein defekter Staging-Server untergraben alle Ihre Entwicklungsbemühungen? Das sind Anzeichen dafür, dass Ihr Ansatz für Testumgebungen in agilen Projekten möglicherweise verbessert werden muss. Andernfalls wird die weitere Veröffentlichung bald zu teuer. Dieser Leitfaden erklärt, wie agiles Testumgebungsmanagement in der Praxis aussieht und wie Sie es implementieren können, um Ihre aktuellen QA-Bedingungen zu verbessern. Er behandelt auch bewährte Praktiken und Tipps sowie gängige Herausforderungen.
Testumgebungen in Agile sind konfigurierte Bereiche zur Validierung von Code vor der Produktion, von lokalen Entwicklungsumgebungen bis hin zu produktionsähnlichen Staging-Umgebungen.
Effektive agile Testumgebungen erfordern Automatisierung von Bereitstellung, Deployment, Datenbefüllung und Abbau durch Infrastructure as Code, um Reproduzierbarkeit zu gewährleisten.
Umgebungskonflikte sind eine große Herausforderung, wenn mehrere Teams begrenzte Ressourcen teilen, was zu Engpässen führt, die die Vorteile paralleler Arbeitsabläufe in Agile untergraben.
Konfigurationsabweichungen zwischen Umgebungen führen zu unzuverlässigen Testergebnissen.
Entdecken Sie, wie Sie sie von frustrierenden Hindernissen in leistungsstarke Enabler für Qualität und Geschwindigkeit verwandeln können 👇
Was sind Testumgebungen in Agile?
Eine Testumgebung ist ein konfiguriertes System, das Hardware, Software, Netzwerktopologie und Daten umfasst. Der Zweck besteht darin, Codeänderungen zu validieren, bevor etwas in die Produktion gelangt.
Im Grunde helfen Testumgebungen dabei herauszufinden, ob sich eine Änderung unter Bedingungen korrekt verhält, die der Produktion nahe genug kommen. Ihre Umgebungsinfrastruktur muss zusammen mit Testumgebungen und anderen QA-Maßnahmen diese Releases unterstützen, ohne zum Engpass zu werden oder, noch schlimmer, zu einem Compliance- oder Investitionsproblem.
Arten von Testumgebungen in Agile
Nur eine Umgebung zu haben, funktioniert für kein Team mehr. Was Sie tatsächlich benötigen, ist ein mehrstufiger Aufbau, bei dem jede Schicht einen bestimmten Validierungstyp übernimmt.
Hier ist, was jeder Typ leistet und wo er in die Delivery-Pipeline passt:
Lokale Entwicklungsumgebungen. Diese befinden sich auf einzelnen Entwicklerrechnern und dienen als erste Validierungslinie. Unit-Tests, statische Analyse und schnelle Komponentenchecks laufen hier, bevor eine einzige Codezeile gepusht wird. Geschwindigkeit hat Priorität; Realismus ist zweitrangig.
CI-Umgebungen. Dies sind kurzlebige, pipeline-gesteuerte Umgebungen, die bei jedem Commit oder Pull-Request automatisch hochgefahren werden. Ihre Aufgabe ist es, Regressionen frühzeitig ohne menschliches Eingreifen zu erkennen. Eine gut konfigurierte CI-Umgebung läuft in Minuten und liefert ein klares Pass/Fail-Signal, das direkt mit der Änderung verknüpft ist, die sie ausgelöst hat.
Ephemere Preview-Umgebungen. Solche Umgebungen bieten isolierte Bereiche pro Pull-Request. Sie geben jeder Änderung ihre eigene Sandbox für Integration und funktionale Validierung und beseitigen so die Konflikte, die entstehen, wenn mehrere Teams eine einzige Staging-Instanz teilen. Wenn der PR zusammengeführt wird, wird die Umgebung automatisch zerstört.
Staging-Umgebungen. Staging sind langlebige, produktionsäquivalente Umgebungen, die für die endgültige Validierung vor der Freigabe verwendet werden. Sie spiegeln die Produktion in Bezug auf Infrastrukturkonfiguration, Service-Versionen und Datenform wider. End-to-End-Tests, Performance-Tests und Smoke-Tests laufen hier. Staging ist der Ort, an dem Ihr Team Deployment-Vertrauen aufbaut, nicht wo Sie Featureverhalten debuggen.
UAT-Umgebungen (User Acceptance Testing). UAT-Umgebungen sind stabile Sandboxen, in denen Produktverantwortliche, Geschäftspartner und Endbenutzer die Funktionalität anhand von Akzeptanzkriterien validieren können. Diese Umgebungen priorisieren Stabilität und Datenrealismus, da nicht-technische Benutzer für ihre Überprüfung eine vorhersehbare Schnittstelle benötigen.
Produktionsumgebungen mit schrittweisen Rollout-Mechanismen. Diese repräsentieren ein fortgeschrittenes Muster, bei dem eine kleine Gruppe echter Benutzer neue Funktionen über Feature-Flags oder stufenweise Deployments erhält. Dieser Ansatz deckt Verhaltensweisen wie reale Verkehrsverteilung, Latenz von Drittanbietern und das Verhalten nachgelagerter Abhängigkeiten ab, die niedrigere Umgebungen nicht genau replizieren können.
Jede Stufe fängt eine andere Defektklasse zu unterschiedlichen Kostenpunkten ab. Wie üblich gilt: Je früher ein Defekt erkannt wird, desto günstiger ist die Behebung. Die Gestaltung Ihrer Umgebungsstrategie rund um dieses Prinzip ist der Schlüssel zu Ihrer QA.
Das Management von Testumgebungen in Agile erfordert sowohl Infrastruktur als auch eine zentrale Stelle für Sichtbarkeit und Standardisierung. Hier kann aqua cloud, eine KI-gestützte Test- und Anforderungsplattform, für QA-Teams, die in schnelllebigen Bereitstellungszyklen arbeiten, sehr nützlich sein. Mit aqua können Sie alle Ihre Testumgebungen mit benutzerdefinierten Feldern dokumentieren und verfolgen sowie Tests nach Umgebungskonfigurationen organisieren. Das einheitliche Repository der Plattform schafft vollständige Rückverfolgbarkeit zwischen Ihren Umgebungen, Anforderungen, Testfällen und Ergebnissen. Der domänentrainierte KI-Copilot von aqua generiert umgebungsspezifische Testfälle, die auf Ihrer tatsächlichen Projektdokumentation, Chats oder sogar Sprachnotizen über RAG-Technologie basieren. Auf diese Weise ist jeder KI-Vorschlag für Ihre spezifische Einrichtung relevant. Darüber hinaus integriert sich aqua nativ mit den bereits in Ihrem Tech-Stack vorhandenen Tools, einschließlich Jira, Jenkins und mehr als 12 anderen Tools, sodass Umgebungsdaten einfach in Ihre bestehenden Workflows integriert werden können.
Steigern Sie die Testeffektivität um 80% mit aqua's KI
In vielen Fällen bestimmt die Testumgebung, ob agile Praktiken mit dem tatsächlichen Liefertempo Ihres Teams machbar sind. Ohne die richtige Umgebungsinfrastruktur wird CI zu einer langsamen Warteschlange, TDD zu Reibung und Sprint-Demos zu riskanten Unterfangen. Das Verständnis dessen, was jede Praktik von Ihren Umgebungen fordert, hilft Ihrem Team, eine Infrastruktur zu entwickeln, die zu Ihrer tatsächlichen Arbeitsweise passt.
Rolle 1: Ermöglichung kontinuierlicher Integration
Ohne Testumgebungen: Entwickler integrieren Code selten, Konflikte häufen sich, und Integrationsfehler tauchen spät im Sprint als große, schwer zu debuggende Zusammenführungen auf.
Mit Testumgebungen: Jeder Commit löst einen automatisierten Build und Testlauf in einer sauberen, isolierten CI-Umgebung aus. Fehler werden innerhalb von Minuten erkannt, einer bestimmten Änderung zugeordnet und behoben, bevor sie sich ausbreiten. Der Hauptzweig bleibt stabil und jederzeit einsatzbereit.
Rolle 2: Unterstützung von testgetriebener und verhaltensgetriebener Entwicklung
Ohne Testumgebungen: TDD-Zyklen verlangsamen sich, weil Entwickler auf gemeinsam genutzte Umgebungen warten. BDD-Szenarien können ohne eine stabile Umgebung nicht automatisch ausgeführt werden, sodass sie im Grunde statische Dokumentation sind.
Mit Testumgebungen: Entwickler führen fehlgeschlagene Tests lokal in Sekunden aus, implementieren die Behebung und validieren sie, ohne ihren Workflow zu verlassen. BDD-Szenarien werden automatisch in CI gegen den neuesten Build ausgeführt und geben Produktverantwortlichen und Ingenieuren eine kontinuierlich überprüfte Referenz für das Systemverhalten.
Rolle 3: Ermöglichung paralleler Team-Workflows im großen Maßstab
Ohne Testumgebungen: Ihr Team endet damit, Arbeit um den gemeinsamen Umgebungszugriff herum zu serialisieren. Die explorative Testung einer Gruppe blockiert den Regressionslauf einer anderen, und Hotfix-Deployments warten darauf, dass die Feature-Validierung abgeschlossen wird.
Mit Testumgebungen: Ephemere Preview-Umgebungen geben jedem Arbeitsstrom seinen eigenen isolierten Validierungsraum. Ihre Teammitglieder arbeiten parallel ohne Koordinationsaufwand, und der Umgebungszugriff hört auf, eine Einschränkung für den Durchsatz der Bereitstellung zu sein.
Rolle 4: Unterstützung von Sprint-Demos und Stakeholder-Validierung
Ohne Testumgebungen: Demos laufen auf instabilen gemeinsam genutzten Umgebungen, wo Last-Minute-Änderungen den Build Stunden vor einer Überprüfung brechen können. Infolgedessen wird das Stakeholder-Feedback verzögert, weil das, was sie sehen, nicht die tatsächliche Sprint-Leistung widerspiegelt.
Mit Testumgebungen: Eine dedizierte, stabile Demo-Umgebung wird zu Beginn jeder Sprint-Überprüfung mit einem verifizierten Build aktualisiert. Stakeholder überprüfen das tatsächliche Inkrement. Feedback-Schleifen werden enger und Sprint-Ziele werden wirklich überprüfbar.
Rolle 5: Unterstützung der CI/CD-Deployment-Pipeline
Ohne Testumgebungen: Deployments sind manuell, selten und riskant. Es gibt keine Probestufe vor der Produktion, sodass das Release-Vertrauen gering ist und die Rollback-Raten hoch bleiben.
Mit Testumgebungen: Jede Pipeline-Stufe ist einer zweckgebauten Umgebung zugeordnet, vom Build und Test über Integration, Staging bis zur Freigabe. Deployments werden automatisiert, wiederholbar und in jedem Schritt validiert. Produktionsfreigaben werden Routine.
Schlechte Testumgebungsübergänge zwischen diesen Stufen sind eine häufige Quelle von Bereitstellungsfehlern. Wenn die Übergaben zwischen Umgebungsebenen inkonsistent oder manuell sind, schlüpfen Defekte durch, selbst wenn einzelne Umgebungen gut funktionieren.
Einrichten einer Testumgebung für agile Projekte
Die Einrichtung einer testgetriebenen Umgebung in agilen Projekten ist eine Designaufgabe, die Sie überarbeiten, wenn das Liefertempo und die Systemkomplexität Ihres Teams wachsen. Die folgenden Schritte beschreiben, wie leistungsstarke Teams dieses Problem angehen: beginnend mit dem Zweck, aufbauend auf Automatisierung und Behandlung von Daten und Beobachtbarkeit als Kernanforderungen von Anfang an.
Schritt 1: Definieren Sie den Zweck und die Eigentümerschaft der Umgebung, bevor Sie irgendwelche Tools anfassen
Jede Umgebung benötigt einen definierten Zweck, einen benannten Eigentümer und eine spezifische Benutzergruppe, bevor eine einzige Ressource bereitgestellt wird. Ohne dies werden Umgebungen zu Sammel-Infrastrukturen, bei denen niemand für Zuverlässigkeit verantwortlich ist und jeder betroffen ist, wenn etwas kaputt geht.
Dokumentieren Sie für jede Umgebung Folgendes:
Primärer Benutzer. Ist dies für Entwickler, die Integrationsprüfungen durchführen, QA-Ingenieure, die explorative Tests durchführen, oder Produktverantwortliche, die Akzeptanzkriterien überprüfen? Jede Gruppe hat unterschiedliche Stabilitäts- und Datenanforderungen, so dass die frühzeitige Identifizierung des Hauptbenutzers später widersprüchliche Erwartungen verhindert.
Testtypen, die sie unterstützt. Unit- und Komponententests benötigen Geschwindigkeit; End-to-End-Tests benötigen Produktionsgenauigkeit; UAT benötigt stabile, realistische Daten. Eine Umgebung, die für einen dieser Zwecke gebaut wurde, funktioniert für die anderen schlecht, weshalb gemeinsam genutzte generalistische Umgebungen zu einem wiederkehrenden Engpass werden.
Datenklassifizierung. Synthetische Daten für Feature-Tests, maskierte Produktions-Snapshots für genauigkeitskritische Szenarien oder bereinigte Exporte für Compliance-Validierung. Definieren Sie dies im Voraus, oder Ihr Team wird unter Termindruck inkonsistente Entscheidungen treffen.
Reset- und Wiederherstellungsprotokoll. Wer einen Reset auslöst, wie lange es dauert und in welchen Zustand die Umgebung zurückkehrt. Wenn dies nicht skriptiert und dokumentiert ist, wird die Wiederherstellung jedes Mal, wenn etwas schief geht, zu einem manuellen Prozess.
Ich würde sagen, hören Sie auf, über Ihre Deployment-Ziele als Prod, Staging, QA usw. nachzudenken. Beginnen Sie, über sie einfach als Zielumgebung nachzudenken.
Schritt 2: Kodifizieren Sie jede Umgebung als versionierte Infrastrukturdefinition
Eine Umgebung, die nur als laufende Instanz existiert, ist nur eine undokumentierte manuelle Änderung davon entfernt, nicht reproduzierbar zu werden. Jede Umgebung, auf die sich Ihr Team verlässt, sollte eine entsprechende IaC-Definition haben, geschrieben in Terraform, Pulumi oder CloudFormation, in die Versionskontrolle übertragen und durch eine Pipeline bereitgestellt.
Wenn eine Umgebung abweicht oder kaputt geht, baut Ihr Team sie aus der Definition wieder auf. Jede Änderung an dieser Definition sollte durch einen Pull-Request mit einem Prüfer gehen. Jede Umgebung, die von Hand modifiziert wird, auch „vorübergehend“, hat bereits begonnen abzuweichen.
Ihre IaC-Definition sollte Folgendes abdecken:
Rechenressourcen und Netzwerktopologie
Alle Backing-Services mit expliziten Versionspins, nie „latest“
Umgebungsvariablen und Konfigurationseinbindung über einen Secrets-Manager, keine hartkodierten Werte
Seed-Daten-Skripte, die bei der Bereitstellung automatisch ausgeführt werden
Abbaulogik, damit Umgebungen sich nicht ansammeln, wenn sie aufgegeben werden
Schritt 3: Etablieren und erzwingen Sie Laufzeitparität mit der Produktion
Paritätslücken zwischen Testumgebungen und Produktion sind der Geburtsort umgebungsspezifischer Bugs. Ein Test, der im Staging bestanden wird und in der Produktion fehlschlägt, geht fast immer auf einen Unterschied zurück, den Ihr Team nicht verfolgt hat: eine geringfügige OS-Versionsdiskrepanz, eine Datenbankkollaionseinstellung oder eine Netzwerkrichtlinie, die in der Produktion existiert, aber nicht im Staging.
Definieren Sie eine Paritätsbasislinie, zu deren Aufrechterhaltung sich Ihr Team über alle nicht-lokalen Umgebungen hinweg verpflichtet:
Laufzeitversionen: OS-, Sprachlaufzeit- und Framework-Versionen sollten so festgelegt sein, dass sie genau mit der Produktion übereinstimmen, nicht annähernd
Infrastrukturtopologie: Load-Balancer-Konfiguration, Service-Mesh-Regeln und Netzwerkrichtlinien sollten das Produktionsverhalten replizieren, nicht der Einfachheit halber vereinfacht werden
Backing-Services: Die gleiche Datenbank-Engine mit übereinstimmender Version und Kollationseinstellungen, plus das gleiche Message-Broker- und Caching-Layer-Setup
Bereitstellungsmechanismus: Umgebungen sollten mit den gleichen Pipeline-Tools wie die Produktion bereitgestellt werden, da Unterschiede in der Art und Weise, wie Artefakte erstellt werden, ihre eigene Klasse von Bugs einführen
Wo volle Parität aufgrund von APIs von Drittanbietern, Kostenbeschränkungen oder Datensensibilität nicht erreichbar ist, dokumentieren Sie die Lücke in der Umgebungsdefinition und notieren Sie, welche Testkategorien diese Lücke betrifft.
Schritt 4: Behandeln Sie Testdaten als versioniertes Artefakt
Veraltete Testdaten sind eine der häufigsten Ursachen für unzuverlässige Testergebnisse und bleiben oft lange unbemerkt. Wenn Umgebungen mit Datensätzen laufen, die niemand aktiv pflegt, werden Randfälle übersehen und Fehler dem Code angelastet. Aber der Code ist oft in Ordnung. Die Daten spiegeln nicht mehr wider, wie das Produkt tatsächlich funktioniert.
Eine praktische Testdatenstrategie für agile Testumgebungen sieht so aus:
Synthetische Daten für funktionale Tests: Generieren Sie vorhersehbare, PII-freie Datensätze mit Tools wie Faker oder Factory-Bibliotheken. Diese setzen sich sauber zurück, versionen neben dem Code und decken die meisten Testszenarien ohne Datenschutzrisiko ab.
Maskierte Produktions-Snapshots für komplexe Szenarien: Für Tests, die realistische Datenvolumina oder referenzielle Integrität benötigen, verwenden Sie anonymisierte Produktionsexporte. Führen Sie diese durch eine Maskierungs-Pipeline wie Neosync oder Delphix, bevor sie eine Nicht-Produktionsumgebung berühren.
Seed-Skripte in der Versionskontrolle: Jeder Umgebungsbereitstellungslauf sollte ein Seed-Skript ausführen, das einen bekannten Datensatz lädt. Das Skript lebt im selben Repo wie die IaC-Definition und wird aktualisiert, wenn sich das Datenmodell ändert.
Automatisierte Auffrischungszeitpläne: Veraltete Snapshots bauen mit der Zeit Schema-Drift auf. Planen Sie automatisierte Auffrischungen, wöchentlich für Staging und pro PR für ephemere Umgebungen, damit Umgebungen nicht leise von den tatsächlichen Datenformen Ihrer Anwendung abweichen.
Schritt 5: Instrumentieren Sie Umgebungen für Beobachtbarkeit vor dem ersten Testlauf
Wenn ein Test in CI fehlschlägt, ist die erste Frage einfach: Handelt es sich um einen Produktfehler oder um ein Infrastrukturproblem? Ohne umgebungsebenenspezifische Beobachtbarkeit gehen die meisten Teams einfach davon aus, dass es sich um ein Code-Problem handelt. Also graben sich Ingenieure in eine perfekt gesunde Codebasis ein. Sie verbringen Stunden damit, ein Problem zu jagen, das nie da war. In der Zwischenzeit sitzt die wahre Ursache verborgen. Ein falsch konfigurierter Service. Ein Netzwerk-Timeout. Etwas völlig außerhalb des Codes. Das ist die Lücke, die Umgebungsbeobachtbarkeit schließt.
Jede Umgebung sollte mit Folgendem ausgestattet sein:
Strukturierte Protokollierung mit einem konsistenten Format über alle Dienste hinweg, gesendet an einen zentralen Log-Aggregator wie ELK Stack oder Datadog Logs
Infrastrukturmetriken zur Abdeckung von CPU, Speicher und Netzwerkdurchsatz auf Umgebungsebene.
Verteiltes Tracing über Dienstgrenzen hinweg, damit Fehler auf eine bestimmte Dienstinteraktion zurückgeführt werden können.
Separate Alarmierung zur Umgebungsgesundheit. Wenn die Bereitstellungszeit einer Umgebung ihr vereinbartes Limit überschreitet oder ihre Fehlerrate ohne Codeänderung ansteigt, sollte Ihr Team dies vor dem nächsten Testlauf wissen
Schritt 6: Machen Sie Umgebungsbereitstellung und -abbau zu Pipeline-nativen Operationen
Manuelle Bereitstellungsschritte in Ihrer Delivery-Pipeline sind eine sich wiederholende Aufgabe. Jeder manuelle Schritt fügt Wartezeit hinzu, führt Inkonsistenz zwischen Läufen ein und schafft eine Abhängigkeit von demjenigen, der das Wissen darüber hat, wie es zu tun ist. Über einen Sprint-Zyklus summiert sich das zu Stunden verlorener Zeit.
Umgebungsbereitstellung, Testausführung und Abbau sollten alle automatisch basierend auf Pipeline-Ereignissen ausgelöst werden:
Zusammenführung zum Hauptzweig: Staging-Bereitstellung automatisch ausgelöst, Smoke-Tests ausgeführt, Ergebnis zum PR gepostet
Time-to-live (TTL)-Richtlinien behandeln Umgebungen, die aufgegeben werden. Setzen Sie eine maximale Lebensdauer, wie z.B. 48 Stunden für Preview-Umgebungen, und erzwingen Sie automatischen Abbau über Ihren Infrastruktur-Scheduler. Ohne TTL-Richtlinien häufen sich ungenutzte Umgebungen und treiben die Cloud-Kosten in die Höhe.
Für weitere Einblicke in Testumgebungsübergänge erkunden Sie andere unserer Ressourcen, die detaillierte Strategien für reibungslosere agile Prozesse bieten.
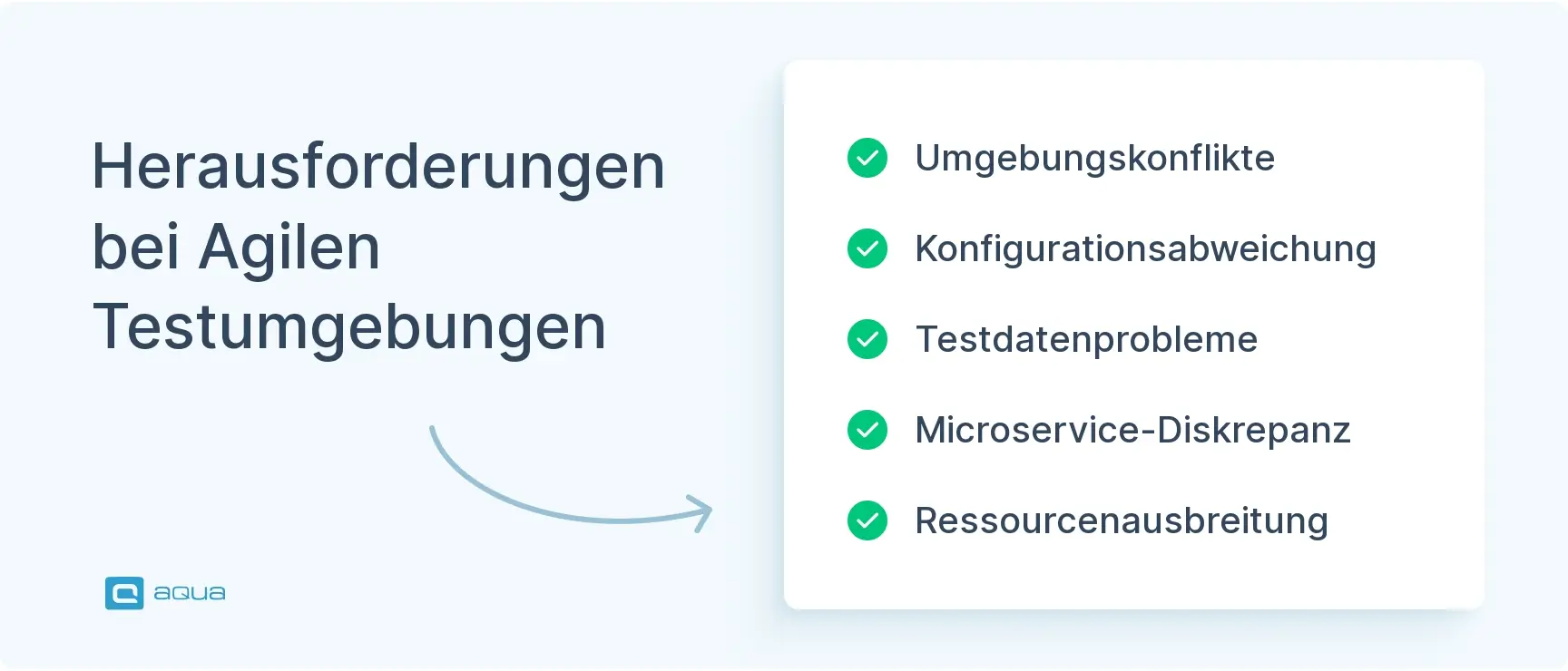
Herausforderungen beim Management von Testumgebungen in Agile
Selbst gut strukturierte Umgebungen stoßen unter realem Lieferdruck auf Reibung. Die fünf unten genannten Probleme machen den Großteil der umgebungsbezogenen Verzögerungen aus, mit denen Ihr Team konfrontiert sein wird. Sie frühzeitig zu erkennen, wird dringend empfohlen, um die Kosten für Nacharbeit zu optimieren.
1. Umgebungskonflikte
Wenn Ihr Team eine einzige Staging-Umgebung über mehrere Arbeitsabläufe hinweg teilt, wartet immer jemand. Ein Hotfix sitzt in der Warteschlange hinter einem Feature, das gerade validiert wird. Explorative Tests werden verkürzt, um Platz für einen Regressionslauf zu schaffen. Parallele Arbeit wird seriell, der Sprint-Durchsatz sinkt, und Ihr Team sieht das Muster normalerweise nicht, weil die Verzögerungen über kleine, stille Wartezeiten verteilt sind.
Lösung: Stellen Sie ephemere Preview-Umgebungen pro Pull-Request bereit. Jede Änderung bekommt ihren eigenen isolierten Raum, und gemeinsames Staging bleibt nur für endgültige Vor-Produktionsprüfungen reserviert.
2. Konfigurationsabweichung
Langlebige Umgebungen sammeln Änderungen, die nie zurück in die IaC-Definition gelangen: eine schnelle Behebung auf dem Server, ein manuell aktualisierter Konfigurationswert, eine Service-Version, die angehoben wurde, um einen Test zu entsperren. Über Wochen hinweg entfernt sich Staging leise von der Produktion. Tests bestehen, wo sie fehlschlagen sollten, und Bugs erreichen die Produktion, die viel früher hätten erkannt werden sollen. Drift bleibt unsichtbar, bis es einen echten Vorfall verursacht, was es teuer macht.
Lösung: Behandeln Sie jede manuell modifizierte Umgebung als unzuverlässig. Bauen Sie aus der IaC-Definition neu auf und erzwingen Sie eine Richtlinie, dass Konfigurationsänderungen einen Pull-Request erfordern, nicht direkten Serverzugriff.
3. Testdatenverschlechterung
Das Ausführen von Tests gegen veraltete oder inkonsistente Daten erzeugt Fehler, die wie Code-Defekte aussehen, es aber nicht sind. Ihr Team verbringt Stunden mit Bugs, die nicht existieren, während das eigentliche Datenproblem stillschweigend jeden Testlauf danach beeinflusst. In regulierten Sektoren schafft dies auch Compliance-Risiken, wenn Umgebungen Daten halten, die sie nicht sollten.
Lösung: Versionieren Sie Testdatensätze neben dem Code, automatisieren Sie Auffrischungszeitpläne und verwenden Sie synthetische Datengeneratoren für die meisten funktionalen Tests. Eine dedizierte Lösung wie aqua gibt Ihrem Team einen zentralen Ort, um nachzuverfolgen, welche Datensätze mit welchen Testfällen und Umgebungen verknüpft sind, wodurch datenbezogene Fehler von wiederkehrenden Mysterien zu nachvollziehbaren, behebbaren Ereignissen werden.
4. Mikroservices-Synchronisation
In einem verteilten System erstreckt sich Ihre Umgebung über viele Dienste, jeder mit seiner eigenen Version und Konfiguration. Eine Diskrepanz zwischen zwei nachgelagerten Serviceversionen kann zu Ausfällen über einen gesamten Testlauf hinweg kaskadieren. Die Diagnose bedeutet typischerweise, durch mehrere Service-Logs gleichzeitig zu verfolgen, was Ihre Ingenieure jeden Sprint erhebliche Zeit kostet.
Lösung: Pflegen Sie eine klare Service-Versionsreferenz pro Umgebungsebene in der Versionskontrolle. Kombinieren Sie dies mit Contract-Testing für Schnittstellenvalidierung und Service-Simulation für nicht verfügbare Abhängigkeiten.
5. Kosten- und Ressourcenausbreitung
Ephemere Umgebungen lösen Konflikte, erzeugen aber ein anderes Problem. Ohne Lebenszyklusmanagement häufen sie sich an. Aufgegebene Instanzen erhöhen stillschweigend Ihre Cloud-Rechnung, und verwaiste Umgebungen können veraltete Daten oder alte Service-Versionen enthalten, die aktive Testläufe beeinträchtigen.
Lösung: Erzwingen Sie TTL-Richtlinien und automatischen Abbau auf Pipeline-Ebene. Setzen Sie Pro-Team-Ressourcenlimits und überprüfen Sie Kostenberichte jeden Sprint.
Gutes Testumgebungsmanagement adressiert diese Herausforderungen durch klare Prozesse und Eigentümerschaft, nicht durch Hinzufügen von mehr Infrastruktur.
Best Practices für effektives Testen in agilen Umgebungen
Die folgenden Praktiken adressieren, was tatsächlich Umgebungen unter anhaltendem Lieferdruck beeinträchtigt, und gehen über die Grundlagen der Einrichtung hinaus, die die meisten Teams bereits kennen.
1. Verfolgen Sie die Fehlerzuordnungsrate
Die meisten Teams verfolgen, ob Tests bestehen. Weniger verfolgen, warum sie fehlschlagen. Umgebungsfehler und Produktdefekte sehen in einem Standard-Testbericht identisch aus, so dass Ihr Team Infrastrukturprobleme als Code-Bugs untersucht. Markieren Sie jeden Pipeline-Fehler als entweder „Produkt“ oder „Umgebung“ und überprüfen Sie die Aufteilung wöchentlich. Eine steigende Umgebungsfehlerrate ist ein frühes Signal dafür, dass die Infrastruktur sich verschlechtert, bevor sie beginnt, Sprints zu blockieren.
2. Ordnen Sie Testtypen explizit Umgebungsebenen zu
Jeden Test in jeder Umgebung auszuführen, erzeugt gleichzeitig langsame Pipelines und Abdeckungslücken. Die richtige Zuordnung sieht so aus:
Unit- und Komponententests: Nur CI, Ergebnisse in Sekunden
Integrations- und Contract-Tests: Ephemere Preview-Umgebungen, pro PR
End-to-End- und Performance-Tests: Staging, nur vor der Freigabe
Definieren Sie diese Zuordnung in Ihrer Pipeline-Konfiguration und erfordern Sie eine bewusste Überschreibung für jede Abweichung. Dies hält CI schnell, verhindert Konflikte in gemeinsam genutzten Umgebungen und stellt sicher, dass jede Ebene genau das validiert, wofür sie konzipiert ist. Die Verwendung der richtigen agilen Testtools hilft Ihrem Team, diese Grenzen automatisch durchzusetzen.
3. Versionieren Sie Umgebungsdefinitionen neben Feature-Branches
Wenn ein Feature-Branch eine neue Dienstabhängigkeit oder Schemaänderung einführt, muss die Umgebungsdefinition mit geändert werden. Teams, die Umgebungsdefinitionen in einem separaten Repo halten, stoßen regelmäßig auf Preview-Umgebungen, die die Features, die sie testen, nicht unterstützen können. Die Aufbewahrung von Umgebungsdefinitionen im selben Repo wie der Anwendungscode bedeutet, dass jeder PR die richtige Infrastruktur ohne manuelle Koordination bereitstellt.
Hören Sie auf, Tests als eine separate Aktivität vom Codieren zu betrachten. Wenn Sie es als Teil des Überprüfungsprozesses behandeln, verschwindet dies.
4. Setzen Sie explizite Beförderungskriterien zwischen Ebenen
Informell zu entscheiden, wann ein Build von Preview zu Staging befördert werden soll, reduziert die Unsicherheit bereits erheblich. Explizite Kriterien zu definieren, wie eine 98%ige Testbestehensrate und keine offenen Contract-Testfehler, ist der Weg, dies zu tun. Es macht den Qualitätsstandard auch über Sprints hinweg konsistent.
5. Verwenden Sie schrittweise Rollouts für das, was Staging nicht abdecken kann
Einige Systemverhaltensweisen zeigen sich nur unter realen Produktionsbedingungen: tatsächliche Benutzerverkehrsmuster, Variabilität von APIs von Drittanbietern und nachgelagerte Latenz unter echter Last. Staging hat eine strukturelle Genauigkeitsgrenze, die durch Hinzufügen von mehr Ressourcen nicht behoben wird. Für Verhaltensweisen, die von echtem Verkehr abhängen, sind schrittweise Rollouts über Feature-Flags ein Validierungsschritt. Kombiniert mit den oben genannten Praktiken gibt dies Ihrem Team Abdeckung vom Unit-Test bis zum Live-Verkehr, mit klaren Übergaben in jeder Phase.
Die Verwendung einer strukturierten KI-agilen Testmanagement-Lösung hilft Ihrem Team, all diese Praktiken von einem einzigen Ort aus zu verfolgen, durchzusetzen und zu verbessern.
Effektives Testumgebungsmanagement ist bereits ein ausreichend komplexes System, bestehend aus Software und Infrastruktur. Aber allein fehlt ihm eine Orchestrierungsebene. aqua cloud, eine KI-gestützte Test- und Anforderungsmanagementlösung, hat Sie abgedeckt. Es adressiert direkt die oben genannten Herausforderungen, indem es Struktur und Sichtbarkeit für Ihre Umgebungsstrategie bietet. Mit aqua können Sie Umgebungskonfigurationen mit benutzerdefinierten Feldern dokumentieren, umgebungsspezifische Workflows etablieren und vollständige Rückverfolgbarkeit zwischen jeder QA-Komponente, mit der Sie zu tun haben, aufrechterhalten. Der domänentrainierte KI-Copilot von aqua generiert umgebungsbewusste Testfälle in Sekunden mit RAG-Technologie, die auf Ihrer tatsächlichen Projektdokumentation, Chats oder Sprachnotizen basiert. Dies bedeutet bemerkenswert intelligenteres Testen, das die Feinheiten jeder Umgebung in Ihrer Einrichtung berücksichtigt. Die aqua-Plattform integriert sich in Ihre CI/CD-Pipeline durch REST-APIs und Plugins für Tools wie GitLab CI/CD, Jenkins und Jira. Auf diese Weise fließen Ihre Testergebnisse zurück in Ihr zentrales Repository, unabhängig davon, wo Tests ausgeführt werden.
Erreichen Sie 100% Rückverfolgbarkeit mit aquas Funktionalitäten
Zuverlässige Testumgebungen erfordern bewusste Einrichtung und kontinuierliche Wartung, während Ihr System wächst. Ihr Team wird konsequent Defekte früher erkennen und mit mehr Vertrauen ausliefern, wenn Automatisierung, Produktionsparität und strukturiertes Datenmanagement vorhanden sind. Ohne sie werden Sie weiterhin mit denselben Umgebungsfehlern zu kämpfen haben, Sprint für Sprint. Die Gewinnerkombination aus einer Testumgebungsstrategie und einem All-in-One-QA-Management-Tool wie aqua könnte genau das sein, was Ihr Team jetzt am meisten braucht.
Eine Testumgebung in Agile ist ein konfiguriertes System, das Infrastruktur, Laufzeitabhängigkeiten, Dienste und Daten umfasst, in dem Codeänderungen vor der Produktion validiert werden. Im Gegensatz zu traditionellen Wasserfall-Umgebungen, die einmal pro Freigabezyklus eingerichtet werden, werden agile Testumgebungen häufig bereitgestellt, oft automatisch, und sind darauf ausgelegt, kontinuierliche Validierung über kurze Sprint-Zyklen hinweg zu unterstützen.
Welche verschiedenen Arten von Testumgebungen gibt es?
Agile Teams betreiben typischerweise einen gestaffelten Aufbau: lokale Entwicklungsumgebungen für schnelles Feedback auf Unit-Ebene, CI-Umgebungen, die automatisch pro Commit ausgelöst werden, ephemere Preview-Umgebungen, die pro Pull-Request bereitgestellt werden, Staging-Umgebungen, die die Produktion für die endgültige Validierung spiegeln, und UAT-Umgebungen für Stakeholder-Akzeptanztests. Darüber hinaus decken Produktionsumgebungen, auf die über Feature-Flags oder schrittweise Rollouts zugegriffen wird, genauigkeitskritische Validierung ab, die niedrigere Ebenen nicht replizieren können.
Welche verschiedenen Arten von Tests gibt es in Agile?
Agiles Testen umfasst Unit-Tests, Integrationstests, Contract-Tests, End-to-End-Tests, explorative Tests, Performance-Tests und User Acceptance Tests. Diese werden verschiedenen Pipeline-Stufen und Umgebungsebenen zugeordnet. Unit-Tests laufen lokal und in CI, Integrations- und Contract-Tests laufen in Preview-Umgebungen, und End-to-End- und Performance-Tests laufen in Staging- oder produktionsäquivalenten Umgebungen.
Wie kann Testumgebungsmanagement Freigabezyklen in Agile verbessern?
Strukturiertes Testumgebungsmanagement reduziert die beiden häufigsten Probleme bei Freigabezyklen: Umgebungskonflikte und Konfigurationsabweichung. Wenn Ihr Team bei Bedarf Zugriff auf isolierte, produktionsäquivalente Umgebungen mit konsistenten Daten hat, werden Validierungsläufe schneller abgeschlossen und Defekte früher aufgedeckt. Release-Kandidaten erreichen das Staging in besserem Zustand, was die Zeit zwischen Code-Complete und Produktionsbereitstellung verkürzt.
Welche Herausforderungen entstehen bei der Aufrechterhaltung von Testumgebungen in kontinuierlicher Integration?
CI-Umgebungen stehen vor drei anhaltenden Herausforderungen: die Bereitstellung schnell genug zu halten, um Pipeline-Warteschlangenstau zu vermeiden, Umgebungs-Produktions-Parität aufrechtzuerhalten, wenn sich der Produktions-Stack ändert, und Testdatenfrische zu verwalten, damit CI-Ergebnisse zuverlässig bleiben. Teams, die den Zustand der CI-Umgebung getrennt von der Anwendungsgesundheit verfolgen, einschließlich Bereitstellungszeit, Fehlerraten und Fehlerzuordnung, sind viel besser positioniert, um Verschlechterungen zu erkennen, bevor sie den Lieferdurchsatz beeinflussen.
Beginnen Sie Ihre Arbeit nicht mit gewöhnlichen E-Mails: Fügen Sie eine gesunde Dosis an aufschlussreichen Softwaretest-Tipps von unseren QS-Experten hinzu.
Home » Agile in der QS » Testumgebungen in agilen Projekten: Der ultimative Leitfaden
Lieben Sie das Testen genauso wie wir?
Werden Sie Teil unserer Community von begeisterten Experten! Erhalten Sie neue Beiträge aus dem aqua-Blog direkt in Ihre Inbox. QS-Trends, Übersichten über Diskussionen in der Community, aufschlussreiche Tipps — Sie werden es lieben!
Wir sind dem Schutz Ihrer Privatsphäre verpflichtet. Aqua verwendet die von Ihnen zur Verfügung gestellten Informationen, um Sie über unsere relevanten Inhalte, Produkte und Dienstleistungen zu informieren. Diese Mitteilungen können Sie jederzeit wieder abbestellen. Weitere Informationen finden Sie in unserer Datenschutzrichtlinie.
X
🤖 Neue spannende Updates sind jetzt für den aqua KI Assistenten verfügbar! 🎉








































 Bankwesenaqua ALM hilft Banken, die Produktivität beim Testen um mehr als 50 % zu steigern
Bankwesenaqua ALM hilft Banken, die Produktivität beim Testen um mehr als 50 % zu steigern