Chaos Testing: Key Principles, Benefits, and Implementation
Back in 2008, Netflix experienced a major database corruption that knocked out its DVD shipping operation for three days. Instead of just recovering and moving on, they decided to get proactive. They figured if failures were inevitable, why not trigger them intentionally under controlled conditions? This approach eventually evolved into what we now know as chaos testing or chaos engineering. But, how does it work, and still stay relevant? Let's dive into how this approach could transform your testing strategy and help you build more resilient applications.
Chaotic testing is hypothesis-driven, not random. Every experiment starts with a clear expectation of what should happen.
The chaos testing definition covers more than infrastructure. Application, network, dependency, and even team-level failures all fall within its scope.
Start small. A single service or instance is enough to begin learning from.
CI/CD integration turns chaos testing from a one-time activity into a continuous resilience practice.
The metrics that matter most are MTTR, failure detection time, blast radius containment, and availability during experiments.
What is Chaos Testing?
Chaos testing (often called chaos engineering) is a disciplined approach to deliberately introducing failures into your system to test its resilience. But don’t let the name fool you – there’s nothing random or truly chaotic about it.
In essence, it’s a methodology that helps you identify weaknesses in your systems by simulating real-world failure scenarios in a controlled environment. The chaos testing meaning extends beyond simply breaking things; it’s about understanding how systems respond under stress and improving their ability to withstand disturbances.
At its core, chaos testing involves:
Controlled experiments that simulate real-world failures like server crashes, network outages, or latency spikes
Hypothesis-driven methodology where you predict how your system should respond to failures
Proactive discovery of weaknesses before they impact users in production
Building confidence in your system’s ability to withstand turbulent conditions
Unlike traditional testing that verifies correct behavior under ideal conditions, chaos testing asks the uncomfortable question: “What happens when things go wrong?” It’s about understanding your system’s breaking points and fixing them before they break for real.
History of Chaos Testing
The evolution of chaos testing is a fascinating journey that started with one company’s painful experience and developed into a popular engineering discipline:
2008: Netflix suffers a major database corruption incident that prevents DVD shipments for three days. This painful experience becomes the catalyst for developing more resilient systems.
2010: Netflix begins migrating from data centres to AWS cloud infrastructure, dramatically increasing their system complexity.
2011: Netflix creates and deploys Chaos Monkey, a tool that randomly terminates instances in production to verify that services can survive unexpected failures. It’s named after the idea of unleashing a wild monkey with a weapon in your data centre to randomly destroy servers.
2012: Netflix expands with the “Simian Army” – a suite of tools including Latency Monkey (adding delays), Doctor Monkey (detecting unhealthy instances), and Chaos Gorilla (taking down entire Amazon availability zones).
2014: The term “Chaos Engineering” was formally coined by Netflix engineers, establishing it as a discipline rather than just a collection of tools.
2017: The Principles of Chaos Engineering are published, providing a formal framework for conducting chaos experiments across the industry.
2019-2023: Widespread adoption across industries beyond tech, with chaos engineering becoming an essential practice for organisations focused on reliability and resilience.
What’s remarkable about this timeline is how chaos testing evolved from Netflix’s specific needs to a universal practice. The methodology has evolved from randomly terminating servers to a sophisticated discipline with formal principles, dedicated tools, and widespread adoption.
Advantages and Limitations of Chaos Testing
Chaos testing is about preparing for the inevitable. In complex, distributed systems, failures aren’t a matter of if, but when. What chaos testing does is flip the script: instead of waiting for things to go wrong in production, you simulate failures on your own terms to see how your system reacts.
One of the biggest payoffs is resilience. When you routinely inject failure and monitor the response, your system naturally evolves to become more fault-tolerant. Companies like Amazon and Netflix have credited chaos testing for preventing large-scale outages that would’ve otherwise gone unnoticed. It also sharpens your team’s instincts.
Teams that regularly run chaos experiments recover faster from real-world incidents because they’ve been there before, under controlled conditions. The result? Less downtime, smoother user experiences, and higher confidence across engineering and operations. It even shifts your culture: instead of fearing failure, you start designing systems that expect and handle it.
That said, chaos testing isn’t without limitations. If you run it without proper guardrails, it can cause real damage. Poorly planned experiments might bring down systems or affect users if not isolated correctly. There’s also a cost—setting up safe environments, monitoring tools, and crafting realistic scenarios takes time and resources. And while the idea is gaining popularity, not every team is ready to deliberately inject failure; it can meet resistance from those unfamiliar with the approach. Like any method, it works best when used alongside other testing strategies, not in place of them.
In summary:
Pros:
Builds resilience
Boosts recovery speed
Cons:
Requires planning
Not risk-free
Next, we move to what you want to achieve with chaos testing and explain it from different perspectives.
Chaos Testing Objectives
Once you understand the value chaos testing brings, the next step is to get clear on what you’re actually trying to achieve. It’s not about causing disruption for the sake of it. It’s more about exposing weak spots before they take you by surprise. These objectives help guide chaos experiments so they’re focused, safe, and worth the effort:
Verify system resilience by confirming that applications can withstand component failures without a complete system breakdown
Identify single points of failure that could bring down the entire system when they malfunction
Test recovery mechanisms to ensure automatic failover, retries, and circuit breakers work as designed
Validate monitoring and alerting systems are correctly capturing failure conditions
Build organizational confidence in handling unexpected incidents
Improve mean time to recovery (MTTR) by practising failure scenarios regularly
Test disaster recovery procedures in realistic scenarios
Verify graceful degradation of services when dependencies are unavailable
Discover hidden system dependencies that may not be apparent in normal operations
Evaluate performance under partial failure conditions to ensure SLAs can still be met
Strengthen communication channels used during incident response
Test load balancing and auto-scaling capabilities during partial outages
Keeping these objectives in mind will help you design experiments that find real weaknesses, without introducing unnecessary risk. But just as important as what you test is how you approach it. Let’s look at the principles that keep chaos testing controlled, safe, and meaningful.
Chaos Testing Metrics: How to Measure Success
You cannot improve what you do not measure. Chaotic testing without tracking outcomes is just controlled destruction. These are the metrics that tell you whether your system is actually getting more resilient over time.
Mean Time to Recovery (MTTR). How long does it take your system to return to normal after a failure is injected? This is your most important baseline. It should decrease as your resilience improves.
Failure detection time. How quickly did your monitoring catch the injected failure? A slow detection gap is a monitoring problem, not just a resilience problem.
Error budget consumption. How much of your reliability target was used up during experiments compared to real incidents?
Blast radius containment. Did the failure stay within the expected scope, or did it spread further than anticipated?
Availability during experiments. Were your SLAs maintained while the chaos test was running?
Track these numbers across multiple experiments, not just individual runs. A single passing test proves very little. A consistent improvement trend proves your system is actually getting stronger.
The Principles of Chaos Testing, or a Guide on How to Carry it Out
Chaos testing works best when it’s guided by a clear, disciplined approach. These principles help teams run meaningful experiments without risking unnecessary disruption. Follow these principles, and you’ll rock your chaos testing efforts.
Define Steady State Behaviour: Start with a clear baseline. Identify what normal system performance looks like: response times, error rates, or key business metrics. This gives you a reference point for measuring the impact of your test.
Form a Clear Hypothesis: Make your expectations explicit. If a service fails, how should the system respond? Writing it down keeps the test focused and lets you measure success objectively.
Simulate Real Failures: Choose scenarios that actually happen in production; things like server crashes, latency spikes, or dependency failures. The closer your test is to reality, the more valuable the outcome.
Test in Production (Carefully): Staging environments rarely behave like the real thing. When possible, run experiments in production with guardrails in place. Limit traffic exposure, isolate the test, and monitor closely.
Minimise Blast Radius: Start small. Target a single instance, a small traffic segment, or a low-risk service. Gradually increase the scope as you build confidence in your system’s response.
Automate and Run Regularly: One-off chaos tests aren’t enough. Apply test automation to them and run them often to catch regressions and keep up with system changes.
Measure System and Business Impact: Don’t stop at CPU or latency metrics. Track how incidents affect users, transactions, or other key business functions. That’s what really matters.
Include a Kill Switch: Always have a quick way to stop the experiment. If things spiral, you need to recover fast, without scrambling.
How to Integrate Chaos Testing into Your CI/CD Pipeline
Chaos testing gives you the most value when it runs automatically as part of your deployment process. Running it manually once every few months is not enough to keep up with how fast systems change.
Here is how to build it into your pipeline step by step:
Start in staging. Run lightweight experiments like instance termination and latency injection automatically every time a build is deployed to staging.
Use CI-compatible tools. LitmusChaos and Chaos Toolkit both offer APIs that connect directly to Jenkins, GitHub Actions, and GitLab CI with minimal setup.
Treat results like test results. Define pass and fail criteria for each experiment the same way you would for a functional test. A failed chaos experiment should block a deployment.
For Kubernetes teams, run chaotic testing as part of pre-production validation. This catches resilience regressions introduced by new deployments before they reach users.
Log everything to your test management system. Experiment results should be visible across releases so you can spot trends, not just check individual runs.
Once your team has built confidence with staging experiments, gradually introduce the same approach into production with proper guardrails and a kill switch in place.
As we explore the principles of chaos testing, you might be wondering how to effectively manage these complex test scenarios alongside your regular testing activities. This is where a robust test management system becomes invaluable. aqua cloud provides a centralised platform for organising both your traditional test cases and chaos experiments with complete traceability. With AI-powered, super-fast test generation capabilities, you can quickly create comprehensive test scenarios that verify your system’s resilience under various failure conditions. aqua’s customisable dashboards give stakeholders real-time visibility into testing progress, while the detailed reporting features help identify patterns in system behaviour during chaos experiments. By keeping all your testing activities, including chaos testing, in one place, you can ensure complete test coverage while maintaining clear connections between requirements, tests, and defects.
Achieve 100% test coverage with consistent processes and comprehensive documentation
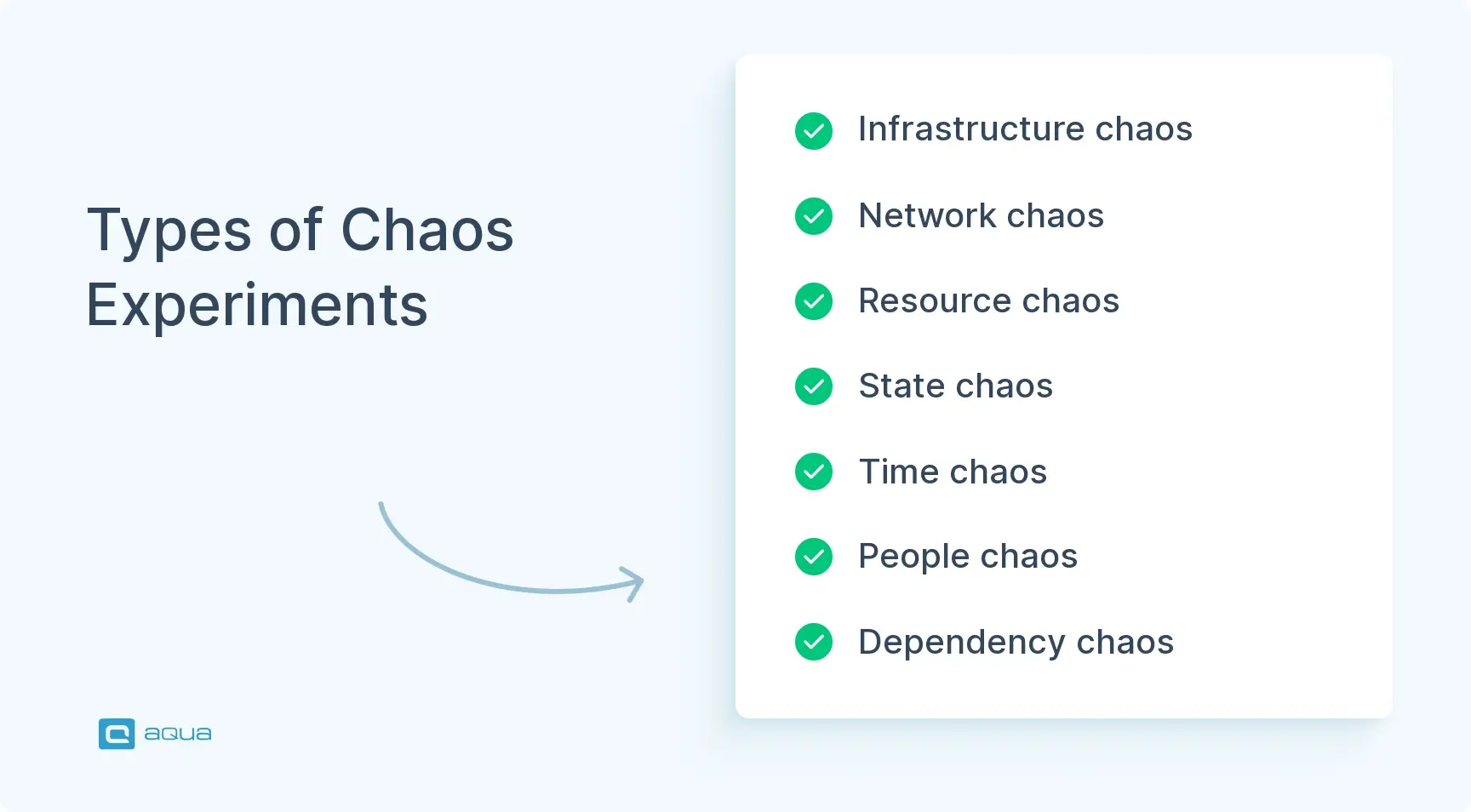
Chaos experiments come in many forms, and each one targets a different kind of weakness. Depending on your system’s architecture and goals, you might focus on infrastructure, data, dependencies, or even your team’s readiness. Here are some of the most common (and useful) types of chaos experiments:
Infrastructure Chaos: Shut down servers, containers, or pods to test how well your system handles a sudden loss. For example, kill a Kubernetes pod at random and watch if traffic reroutes properly.
Network Chaos: Mess with the network: drop packets, add latency, or create service partitions. Simulate a scenario where two services can’t reach each other and see if the system recovers gracefully.
Resource Chaos: Push your servers to the edge. Fill up memory, max out CPU, or exhaust disk space. This helps reveal how your app behaves under pressure and whether it can degrade gracefully.
State Chaos: Tamper with the data. Modify records, inject bad inputs, or simulate data corruption. It’s a powerful way to test validation rules and data-handling logic.
Time Chaos: Shift the system clock forward or backwards. Some applications rely on time-based logic for things like token expiration or scheduled jobs; this helps you catch hidden time-related bugs.
Application Chaos: Deliberately inject faults into your own code. Force an API to fail, simulate exceptions, or block access to internal services. It’s a targeted way to check how your app handles internal breakdowns.
People Chaos: Run a test where a key team member isn’t available. Can others step in? Can incidents still be resolved quickly? This helps identify gaps in on-call coverage and response documentation.
Dependency Chaos: Block third-party services like payment gateways, email APIs, or external authentication. You’ll learn if your system can handle missing dependencies or if it just crashes.
Traffic Chaos: Spike the load. Double the API traffic or simulate thousands of users logging in at once. This shows how your system scales—and whether autoscaling kicks in as expected.
Security Chaos: Simulate attacks or suspicious behaviour. Try flooding endpoints or forcing unexpected input. The goal is to test both your defences and your monitoring systems.
No matter which type you choose, the goal is always the same: detect weaknesses in controlled conditions, before they turn into real problems in production.
What to Know Before Starting Chaos Testing
Before you unleash failure into your systems, even in a controlled way, you need to lay the groundwork. Chaos testing isn’t something you just dive into. It requires preparation, alignment, and a healthy dose of caution.
First, make sure your monitoring setup is solid. You need full visibility into system health before, during, and after the experiment. If something goes wrong, you should be able to detect it in real time, not after customers start complaining.
Every test should begin with a clear hypothesis. What do you expect the system to do if a database goes down or network latency spikes? Having that expectation written down turns chaos into a learning opportunity, not just a random disruption.
You’ll also need buy-in from both leadership and your team. Chaos testing can make people nervous, especially if they think it might trigger a real outage. Get support in advance and make the purpose clear: this is about building resilience, not creating drama.
When you’re ready to run your first experiment, start small. Limit the blast radius to a single instance, a test environment, or a minor service. Have circuit breakers in place and make sure there’s a rollback plan you can execute quickly. It’s not about being paranoid, don’t worry. It’s being responsible.
Choose your timing wisely. Avoid running chaos tests during peak hours or right before major product launches. And make sure your team knows when tests are running and how to respond if things don’t go as expected. Incident response training shouldn’t be optional; it should be a prerequisite.
Finally, document everything. From the hypothesis to the test setup to what actually happened, treat every chaos experiment like a scientific trial. These insights are what make the whole exercise valuable and what help you do it better the next time.
If you prepare well, chaos testing won’t feel like reckless disruption. It’ll feel like confident, deliberate engineering.
Chaos Testing Use Cases and Examples
Chaos testing has moved far beyond theory, leading tech companies to rely on it to validate their systems under real-world pressure. One of the most cited pioneers is Netflix, which regularly terminates random microservice instances in production using its “Chaos Monkey” tool. This helps ensure that other instances can pick up the load without affecting user experience, which is a critical capability in a streaming platform with global traffic.
Intuit applies chaos testing to its Kubernetes infrastructure, randomly deleting pods to verify that critical applications, like its tax filing platform, can recover automatically. This kind of resilience testing is especially vital during high-stakes seasons like tax deadlines, when uptime is non-negotiable.
In the financial sector, banks and trading platforms often simulate primary database outages to test automatic failover systems. The goal is to keep transactions running smoothly, even when core infrastructure fails, because downtime in finance doesn’t just mean frustration; it means lost money and trust.
E-commerce platforms like Amazon simulate third-party service outages, such as payment processor failures, during checkout. These tests verify that fallback mechanisms work correctly, ensuring customers can still complete purchases without being impacted by external service disruptions.
Even cloud providers like Microsoft have embraced chaos testing on a larger scale. Azure teams run region-wide failure simulations to verify cross-region redundancy and service continuity, proving that systems can shift workloads seamlessly even in the event of massive disruptions.
These use cases show that chaos testing isn’t just for edge cases—it’s becoming a critical practice for any team that values resilience, stability, and customer trust.
Tools and Frameworks for Chaos Testing
There are dedicated chaos testing tools that will streamline the process. Choosing the right chaos testing tool depends on your environment, needs, and expertise level. Here’s a comparison of popular options:
Tool
Best For
Key Features
Limitations
Environment
Chaos Monkey
Entry-level server testing
Random instance termination, Open source, Netflix pedigree
Limited failure types, AWS-focused
Cloud (primarily AWS)
Gremlin
Enterprise chaos testing
Wide range of failure types, User-friendly UI, Safety controls
Paid subscription, Some deployment complexity
Multi-cloud, On-prem
LitmusChaos
Kubernetes-native chaos
Kubernetes-specific failures, Extensible with custom experiments, CNCF project
Rich Kubernetes chaos features, Dashboard for visualization, Workflow support
Steep learning curve, Kubernetes-focused
Kubernetes
ChaosBlade
Multi-platform chaos
Support for cloud, container, and application-level chaos, Wide failure coverage
Command-line heavy, Documentation challenges
Multiple platforms
AWS Fault Injection Simulator
AWS service testing
Native AWS integration, Predefined templates, Managed service
AWS-only, Limited customization
AWS only
Pumba
Container network chaos
Simple setup, Good for Docker network testing, Lightweight
Limited to Docker, Fewer failure modes
Docker containers
Chaos Toolkit
Framework-agnostic chaos
Extensible via plugins, Open API specification, Platform-agnostic
More setup required, Less intuitive for beginners
Multiple platforms
When selecting a tool, consider:
Your infrastructure (cloud provider, Kubernetes, etc.)
Types of failures you need to simulate
Required safety features
Integration with your existing monitoring tools
Team expertise and learning curve
Many start with simpler tools like Chaos Monkey for basic instance termination and graduate to more comprehensive platforms like Gremlin or Chaos Mesh as their chaos practice matures. You need to look for solutions that help you execute sophisticated experiments with various degrees of control and monitoring capabilities.
What is a Chaos Testing Pyramid?
The Chaos Testing Pyramid is a conceptual framework that organizes chaos experiments across different system layers, from infrastructure to business processes. Similar to the traditional test pyramid, it suggests where to focus your chaos testing efforts.
At the base of the pyramid is Infrastructure Chaos – the foundation that includes your servers, networks, and cloud resources. This level involves experiments like terminating instances, introducing network latency, or simulating resource exhaustion. These tests are typically easier to automate and run frequently.
The middle layer consists of Application Chaos, focusing on application components like microservices, APIs, and databases. Experiments here include injecting faults into specific services, corrupting data, or triggering error conditions in applications. These tests require deeper understanding of your application architecture.
At the top is Business Process Chaos, which tests end-to-end workflows and user journeys. These experiments verify that critical business functions remain operational during failures. For example, ensuring customers can still complete purchases when the recommendation service is down.
As you move up the pyramid:
Experiments become more complex and specific to your business
Setup requires more cross-team coordination
Potential business impact increases
The frequency of running tests typically decreases
Tests become more difficult to automate
The pyramid helps teams balance their chaos testing efforts, running many infrastructure tests frequently while conducting fewer but more impactful business process experiments at planned intervals.
Chaos Testing vs. Regular Testing
To understand where chaos testing fits into your QA strategy, it helps to compare it directly with traditional testing methods. While both aim to improve software quality, their goals, mindsets, and execution differ significantly.
Aspect
Chaos Testing
Regular Testing
Purpose
Discover how systems fail and improve resilience
Verify correct functionality against requirements
Focus
System behavior during unexpected failures
Expected behavior under normal conditions
Approach
Proactively inject faults and observe system response
Execute predefined test cases with expected outcomes
Environment
Ideally production (with safeguards) or production-like
Usually test or staging environments
Predictability
Often introduces random or unexpected conditions
Typically follows deterministic, repeatable steps
Success Criteria
System degrades gracefully and recovers
System behaves correctly according to specifications
Test Design
Hypothesis-driven experiments
Requirements-driven test cases
Scope
Usually system-wide or involving multiple components
Often focused on specific components or features
Mindset
“How might this break in unexpected ways?”
“Does this work as designed?”
Risk Level
Higher risk (even with controls)
Lower risk to production systems
Chaos testing complements rather than replaces regular testing. While traditional testing verifies that your system works correctly, chaos testing ensures it fails gracefully when the unexpected happens, making the two approaches perfect partners in a comprehensive testing strategy.
Chaos Testing vs Load Testing
Chaos testing is also frequently compared with load testing, but they serve different purposes. One tests how your system handles internal disruptions; the other checks performance under external pressure. Here’s how they differ:
Aspect
Chaos Testing
Load Testing
Primary Goal
Test resilience against component failures
Test performance under heavy user loads
Scenarios
Server crashes, network issues, dependency failures
High traffic, concurrent users, peak activity
What It Breaks
Components and dependencies
Performance thresholds
Metrics Focus
Error handling, recovery time, availability
Response time, throughput, resource utilization
Timing
Can run during normal operation (with safeguards)
Often scheduled during off-hours
Hypothesis
“Will the system survive when X fails?”
“Can the system handle Y users simultaneously?”
Failure Mode
Component unavailability or degradation
Slow performance or complete overload
Duration
Often brief but can be extended
Typically sustained over longer periods
Tools
Chaos Monkey, Gremlin, LitmusChaos
JMeter, LoadRunner, Gatling
Key Question
“Can we survive failures?”
“How many users can we support?”
While load testing pushes systems to their capacity limits, chaos testing deliberately breaks components to test recovery. For comprehensive resilience, consider combining both approaches inchaos performance testing to simulate real-world scenarios where failures often happen during peak traffic. This helps you verify that your system can maintain performance standards even when components fail under load.
When creating a comparison between resilience testing vs chaos testing, you should understand that resilience testing is a broader category that includes various techniques to verify a system’s ability to withstand and recover from failures. Chaos testing is a specific approach within resilience testing that focuses on deliberately injecting failures to test system’s response.
Conclusion
Remember that effective chaos testing starts small. Begin with controlled experiments in non-critical environments, establish a clear hypothesis, and gradually expand your chaos practice as confidence grows. The principles we’ve outlined – defining steady state, minimising blast radius, running in production when possible, and automating experiments – provide a solid foundation. This way, you’re building stronger systems and more capable teams. Are you ready to unleash some productive chaos on your systems? Your future self – the one not getting that 3 AM outage call – will thank you.
Ready to implement chaos testing in your organisation but concerned about managing the complexity? aqua cloud streamlines the entire process from planning your chaos experiments to analysing results. Our centralised test management system helps you document your steady-state metrics, track hypotheses, and record detailed observations from each experiment. With aqua’s collaborative features, your entire team stays informed about upcoming chaos tests through notifications and comments. The platform’s powerful reporting capabilities make it easy to identify patterns across multiple chaos experiments and demonstrate improved system resilience to stakeholders. And with full traceability between requirements, tests, and defects, you can verify that your system’s resilience meets both technical and business objectives. aqua’s robust audit logging also provides comprehensive documentation of all testing activities, essential for regulated industries where resilience testing must be thoroughly documented.
Save up to 40% of your QA time while building more resilient systems with complete test coverage
A common example is randomly terminating server instances in production to verify that your service continues functioning normally. Netflix’s Chaos Monkey does exactly this – it randomly shuts down production servers to ensure their streaming service remains available through redundancy and automatic recovery.
What is the difference between chaos testing and stress testing?
Stress testing pushes a system to its limits with extreme loads to find breaking points, while chaos testing deliberately breaks components to test resilience. Stress testing asks “how much can the system handle?” while chaos testing asks, “What happens when parts of the system fail?”
Why do we do chaos testing?
We perform chaos testing to proactively discover weaknesses in our systems before they cause real outages. By deliberately injecting failures in controlled environments, teams can build more resilient systems, improve recovery procedures, and develop confidence in handling unexpected incidents.
What are the four steps that need to be done in chaos testing?
The four essential steps are: 1) Define the system’s normal “steady state” behavior, 2) Form a hypothesis about how the system will respond to a specific failure, 3) Run an experiment that introduces that failure while monitoring system response, and 4) Analyze results and make improvements to address any weaknesses discovered.
What are the principles of chaos testing?
The core principles include: defining steady state behaviour, forming a hypothesis, minimising blast radius, running experiments in production (when possible), automating experiments, and having a kill switch to stop experiments if they cause unexpected harm. These principles ensure that chaos testing is conducted as a controlled, scientific process rather than random destruction.
How is chaos testing different from chaos engineering?
Chaos engineering is the overall discipline. It is the set of principles and practices that guide how teams build resilient systems through controlled experimentation. Chaos testing is the practical side of that discipline. It refers to the actual experiments you run, the failures you inject, and the observations you record.
Think of it this way: chaos engineering is the strategy, chaos testing is the execution. In practice, many people use the two terms interchangeably, but when building a program from scratch, the distinction helps. You adopt chaos engineering as a philosophy, then use chaos testing as the tool to put it into practice.
How often should chaos tests be run?
The right frequency depends on which layer of the system you are testing and how mature your chaos practice is.
Infrastructure experiments like instance termination and latency injection can run continuously in staging and on a regular weekly schedule in production with proper guardrails in place.
Application and dependency tests fit well into a per-release or weekly cadence.
Business process experiments, which involve higher risk and cross-team coordination, are typically run monthly or quarterly.
Teams that are new to chaos testing should focus on consistency first. Running a small experiment every week is more valuable than running a large one every six months.
Home » Test Automation » Chaos Testing: Key Principles, Benefits, and Implementation
Do you love testing as we do?
Join our community of enthusiastic experts! Get new posts from the aqua blog directly in your inbox. QA trends, community discussion overviews, insightful tips — you’ll love it!
We're committed to your privacy. Aqua uses the information you provide to us to contact you about our relevant content, products, and services. You may unsubscribe from these communications at any time. For more information, check out our Privacy policy.
X
🤖 Exciting new updates to aqua AI Assistant are now available! 🎉













































{kind=link}